1.Numbers
1.1.Number sets
Several types of numbers have been introduced in mathematics to express different types of quantities, and the following will be used throughout this text:
-
The set of natural numbers, , infinite and countable, ;
-
The set of integers, , infinite and countable;
-
The set of rational numbers , infinite and countable;
-
The set of real numbers, infinite, not countable, can be ordered;
-
The set of complex numbers, , infinite, not countable, cannot be ordered.
These sets of numbers form a hierarchy, with . The size of a set of numbers is an important aspect of its utility in describing natural phenomena. The set has three elements, and its size is defined by the cardinal number, . The sets have an infinite number of elements, but the relation
defines a one-to-one correspondence between and , so these sets are of the same size denoted by the transfinite number (aleph-zero). The rationals can also be placed into a one-to-one correspondence with , hence
In contrast there is no one-to-one mapping of the reals to the naturals, and the cardinality of the reals is (Fraktur-script c). Intuitively, there are exponentially more reals than naturals, formally stated in set theory as .
1.2.Quantities described by a single number
The above numbers and their computer approximations are sufficient to describe many quantities encountered in applications. Typical examples include:
-
the position of a point on the unit line segment , approximated by the floating point number , to within machine epsilon precision, ;
-
the measure of resistance to change of the rate of motion known as mass, , ;
-
the population of a large community expressed as a float , even though for a community of individuals the population is a natural number, as in “the population of the United States is , i.e., 328.2 million”.
In most disciplines, there is a particular interest in comparison of two quantities, and to facilitate such comparison a common reference is used known as a standard unit. For measurement of a length , the meter is a standard unit, as in the statement , that states that is obtained by taking the standard unit ten times, . The rules for carrying out such comparisons are part of the definition of real and rational numbers.
1.3.Quantities described by multiple numbers
Other quantities require more than a single number. The distribution of population in the year 2000 among the alphabetically-ordered South American countries (Argentina, Bolivia,..,Venezuela) requires 12 numbers. These are placed together in a list known in mathematics as a tuple, in this case a 12-tuple , with the population of Argentina, that of Bolivia, and so on. An analogous 12-tuple can be formed from the South American populations in the year 2020, say . Note that it is difficult to ascribe meaning to apparently plausible expressions such as since, for instance, some people in the 2000 population are also in the 2020 population, and would be counted twice.
2.Vectors
2.1.Vector spaces
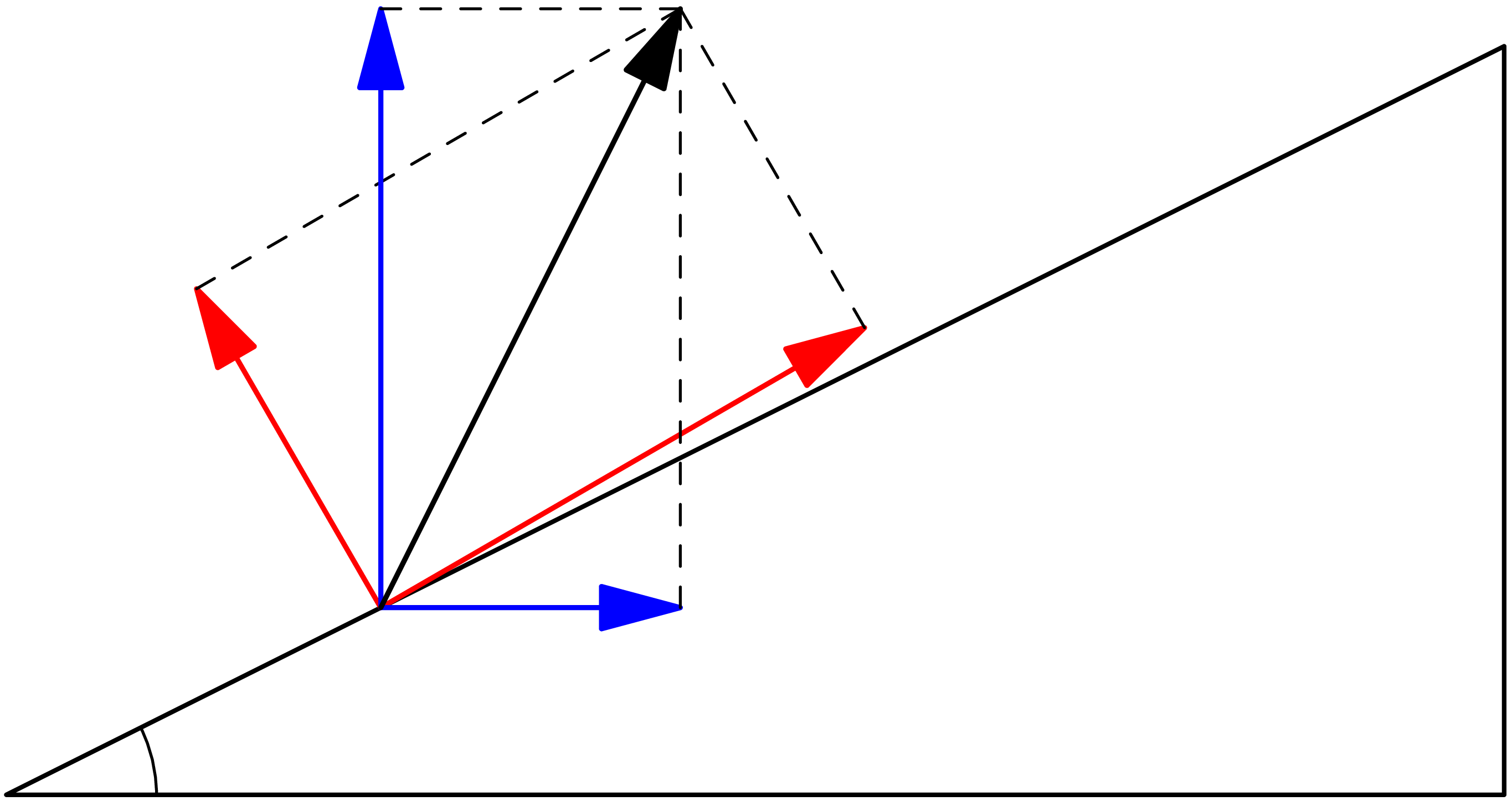
In contrast to the population 12-tuple example above, combining multiple numbers is well defined in operations such as specifying a position within a three-dimensional Cartesian grid, or determining the resultant of two forces in space. Both of these lead to the consideration of 3-tuples or triples such as the force . When combined with another force the resultant is . If the force is amplified by the scalar and the force is similarly scaled by , the resultant becomes
It is useful to distinguish tuples for which scaling and addition is well defined from simple lists of numbers. In fact, since the essential difference is the behavior with respect to scaling and addition, the focus should be on these operations rather than the elements of the tuple.
The above observations underlie the definition of a vector space by a set whose elements satisfy scaling and addition properties, denoted all together by the 4-tuple . The first element of the 4-tuple is a set whose elements are called vectors. The second element is a set of scalars, and the third is the vector addition operation. The last is the scaling operation, seen as multiplication of a vector by a scalar. Vector addition and scaling operations must satisfy rules suggested by positions or forces in three-dimensional space, which are listed in Table 1. In particular, a vector space requires definition of two distinguished elements: the zero vector , and the identity scalar element .
The definition of a vector space reflects everyday experience with vectors in Euclidean geometry, and it is common to refer to such vectors by descriptions in a Cartesian coordinate system. For example, a position vector within the plane can be referred through the pair of coordinates . This intuitive understanding can be made precise through the definition of a vector space , called the real 2-space. Vectors within are elements of , meaning that a vector is specified through two real numbers, . Addition of two vectors, , is defined by addition of coordinates . Scaling by scalar is defined by . Similarly, consideration of position vectors in three-dimensional space leads to the definition of the , or more generally a real -space , , .
2.2.Real vector space
Column vectors.
| (1) |
with the components arranged vertically and enclosed in square brackets. Given two vectors , and a scalar , vector addition and scaling are defined in by real number addition and multiplication of components
| (2) |
The vector space is defined using the real numbers as the set of scalars, and constructing vectors by grouping together scalars, but this approach can be extended to any set of scalars , leading to the definition of the vector spaces . These will often be referred to as -vector space of scalars, signifying that the set of vectors is . Note that a vector with a single component, , is identical to a scalar
and the real line is a simple example of a vector space.
To aid in visual recognition of vectors, the following notation conventions are introduced:
-
vectors are denoted by lower-case bold Latin letters: ;
-
scalars are denoted by normal face Latin or Greek letters: ;
-
the components of a vector are denoted by the corresponding normal face with subscripts as in equation (1);
-
related sets of vectors are denoted by indexed bold Latin letters: .
In Julia, successive components placed vertically are separated by a semicolon.
∴ |
[1; 2; -1; 2] |
(3)
∴ |
The equal sign in mathematics signifies a particular equivalence relationship. In computer systems such as Julia the equal sign has the different meaning of assignment, that is defining the label on the left side of the equal sign to be the expression on the right side. Subsequent invocation of the label returns the assigned object. Components of a vector are obtained by enclosing the index in parantheses.
∴ |
u=[1; 2; -1; 2]; u |
(4)
∴ |
Row vectors.
and is the notation used to denote a row vector. In Julia, horizontal placement of successive components in a row is denoted by a space.
∴ |
uT=transpose(u) |
(5)
∴ |
Compatible vectors.
∴ |
uT=[1 0 1 2]; vT=[2 1 3 -1]; wT=uT+vT |
(6)
∴ |
rT=[1 2]; uT+rT |
DimensionMismatch
∴ |
2.3.Working with vectors
Ranges.
∴ |
m=4; 1:m |
(7)
∴ |
m:-1:2 |
(8)
∴ |
r=0; s=0.2; t=1; (r:s:t)' |
(9)
∴ |
r=0; s=0.3; t=1; (r:s:t)' |
(10)
∴ |
r=0; s= -0.2; t=1; (r:s:t)' |
(11)
∴ |
Visualization.
∴ |
t=LinRange(0,1.5,10); y=sin.(t) |
(12)
∴ |
Indeed, such a piece-by-piece approach is not the way humans organize large amounts of information, preferring to conceptualize the data as some other entity: an image, a sound excerpt, a smell, a taste, a touch, a sense of balance, or relative position. All seven of these human senses will be shown to allow representation by linear algebra concepts, including representation by vectors.
∴ |
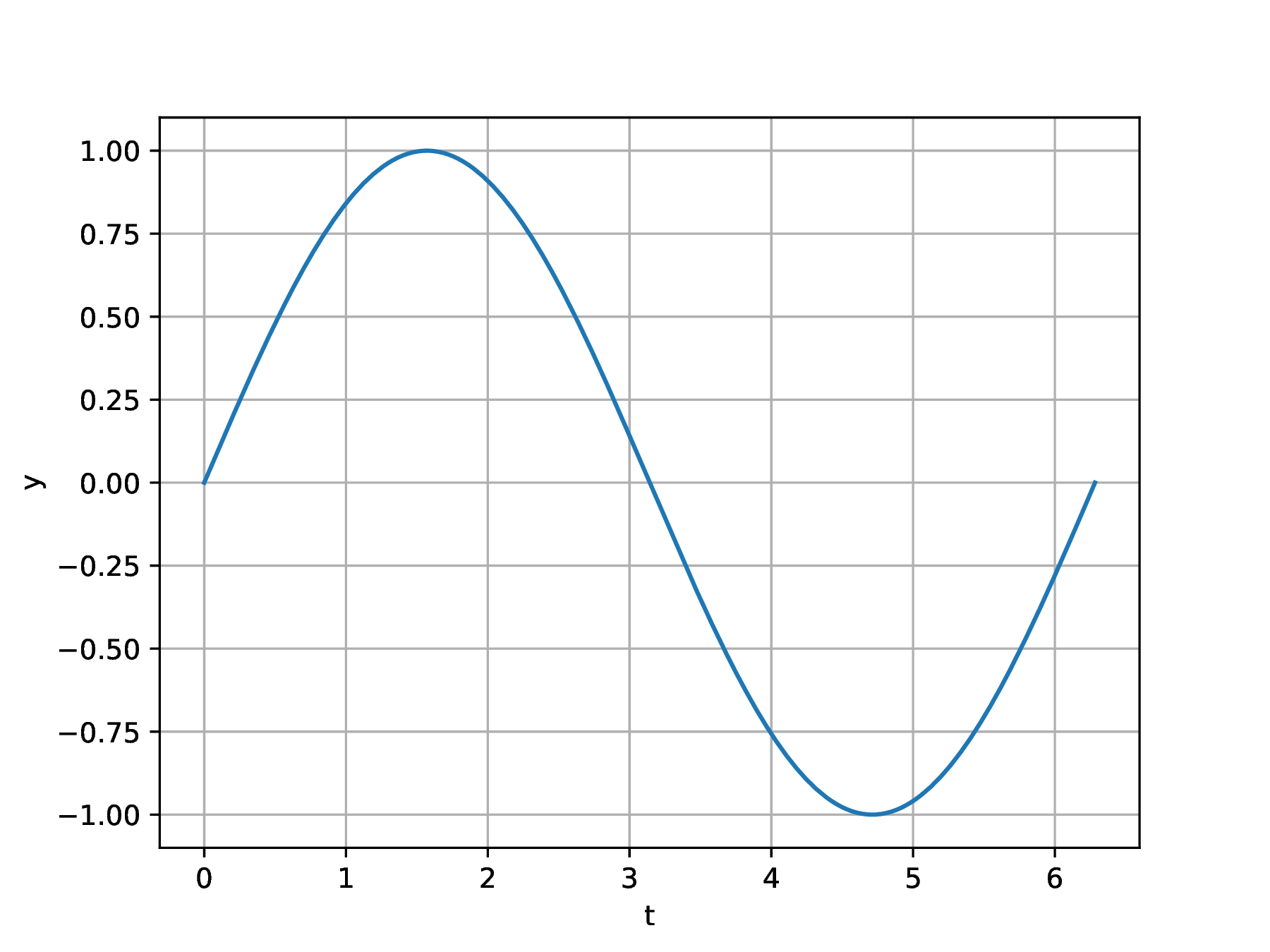
clf(); t=LinRange(0,2*π,180); y=sin.(t); |
∴ |
plot(t,y); grid("on"); xlabel("t"); ylabel("y"); |
∴ |
cd(homedir()*"/courses/MATH347DS/images"); |
∴ |
savefig("L01Fig01.eps"); |
∴ |
3.Matrices
3.1.Forming matrices
The real numbers themselves form the vector space , as does any field of scalars, . Juxtaposition of real numbers has been seen to define the new vector space . This process of juxtaposition can be continued to form additional mathematical objects. A matrix is defined as a juxtaposition of compatible vectors. As an example, consider vectors within some vector space . Form a matrix by placing the vectors into a row,
| (13) |
To aid in visual recognition of a matrix, upper-case bold Latin letters will be used to denote matrices. The columns of a matrix will be denoted by the corresponding lower-case bold letter with a subscripted index as in equation (13). Note that the number of columns in a matrix can be different from the number of components in each column, as would be the case for matrix from equation (13) when choosing vectors from, say, the real space , .
A vector is identical to a matrix with a single column vector
and a scalar is identical to a mtrix with a single column vector that has just one component
3.2.Addition, scaling, transposition of matrices
Since matrices are simply juxtaposition of column vectors, the addition and scaling rules for vectors are carried over for matrices
| (14) |
| (15) |
Similarly, the transpose of a matrix turns column vectors into row vectors
| (16) |
In terms of components
It is readily verified that , , .
3.3.Identity matrix
Consider first , the vector space of real numbers. A position vector on the real axis is specified by a single scalar component, , . Read this to mean that the position is obtained by traveling units from the origin at position vector . Look closely at what is meant by “unit” in this context. Since is a scalar, the mathematical expression has no meaning, as addition of a vector to a scalar has not been defined. Recall that scalars were introduced to capture the concept of scaling of a vector, so in the context of vector spaces they always appear as multiplying some vector. The correct mathematical description is , where is the unit vector . Taking the components leads to , where are the first (and in this case only) components of the vectors. Since , , , one obtains the identity .
Now consider , the vector space of positions in the plane. Repeating the above train of thought leads to the identification of two direction vectors and
∴ |
x=2; y=4; e1=[1; 0]; e2=[0; 1]; r=x*e1+y*e2 |
(17)
∴ |
Continuing the procees to gives
For arbitrary , the components are now rather than the alphabetically ordered letters common for or . It is then consistent with the adopted notation convention to use to denote the position vector whose components are . The basic idea is the same as in the previous cases: to obtain a position vector scale direction by , by ,..., by , and add the resulting vectors.
Juxtaposition of the vectors leads to the formation of a matrix of special utility known as the identity matrix
The identity matrix is an example of a matrix in which the number of column vectors is equal to the number of components in each column vector . Such matrices with equal number of columns and rows are said to be square. Due to entrenched practice an exception to the notation convention is made and the identity matrix is denoted by , but its columns are denoted the indexed bold-face of a different lower-case letter, . If it becomes necessary to explicitly state the number of columns in , the notation is used to denote the identity matrix with columns, each with components.