 |
For the simple scalar mapping , , the condition implies either that or . The function is a linear mapping, and can be understood as defining a zero mapping . When the condition necessarily implies that . Scalar multiplication satisfies the zero product property and if a product is equal to zero one of the factors must be zero.
Linear mappings between vector spaces, , , can exhibit remarkably different behavior. As in the scalar case, a zero mapping is defined by in which case . In contrast to the scalar case, even when , the equation no longer necessarily implies that . For example,
| (1) |
The linear combination above can be read as traveling in the direction of , followed by traveling in the direction of . Since , the net result of the travel is arrival at the origin . Though has two column vectors, they both specify the same direction and are said to contain redundant data. A similar situation arises for
| (2) |
The columns of specify three different directions, but the directions satisfy . This implies that . Whereas the vectors are colinear in , the vectors are coplanar within . In both cases matrix vector multiplication is seen to not satisfy the zero product property and from one cannot deduce that either or . This arises from the defining matrix-vector multiplication to describe linear combinations.
There are however cases when implies that , most simply for the case . The need to distinguish between cases that satisfy or do not satisfy the zero product property leads to a general concept of linear dependence.
Introducing a matrix representation of the vectors
allows restating linear dependence as the existence of a non-zero vector, , such that . Linear dependence can also be written as , or that one cannot deduce from the fact that the linear mapping attains a zero value that the argument itself is zero. The converse of this statement would be that the only way to ensure is for , or , leading to the concept of linear independence.
| (3) |
are , ,…,.
If contains linearly independent vectors the nullspace of only contains one element, the zero vector.
Establishing linear independence through the above definition requires algebraic calculations to deduce that necessarily implies , ,…,. There is an important case suggested by the behavior of the column vectors of the identity matrix that simplifies the calculations. Distinct column vectors within are orthogonal
and each individual vector is of unit 2-norm
In this case multiplying the equation by immediately leads to , and the column vectors of are linearly independent. In general any orthogonal set of vectors are linearly independent by the same argument. In matrix terms, the vectors are collected into a matrix and
An especially simple and useful case is when the norms of all orthogonal vectors are equal to one.
Somewhat confusingly a square matrix with orthonormal columns is said to be orthogonal.
Example. The rotation matrix in is orthogonal,
Example. A rotation matrix in is orthogonal,
Example. The reflection matrix across direction of unit norm in
is orthogonal
since .
Vector spaces are closed under linear combination, and the span of a vector set defines a vector subspace. If the entire set of vectors can be obtained by a spanning set, , extending by an additional element would be redundant since . Avoinding redundancy leads to a consideration of a minimal spanning set. This is formalized by the concept of a basis, and also allows leads to a characterization of the size of a vector space by the cardinality of a basis set.
are linearly independent;
.
The above definitions underlie statements such as “ represents three-dimensional space”. Since any can be expressed as
it results that is a spanning set. The equation leads to
hence are independent, and therefore form a basis. The cardinality of the set is equal to three, and, indeed, represents three-dimensional space.
The domain and co-domain of the linear mapping , , are vector spaces. Within these vector spaces, subspaces associated with the linear mapping are defined by:
the column space of ,
the row space of ,
the null space of ,
the left null space of , or null space of , .
The dimensions of these subspaces arise so often in applications to warrant formal definition.
The dimension of the row space is equal to that of the column space. This is a simple consequence of how scalars are organized into vectors. When the preferred organization is into column vectors, a linear combination is expressed as
The same linear combination can also be expressed through rows by taking the transpose, an operation that swaps rows and columns,
Any statment about the linear combination of column vectors also holds for the linear combination of row vectors . In particular the dimension of the column space equals that of the row space.
The first forays of the significance of matrix-associated subspaces through geometry of lines or planes is useful, but belie the utility of these concepts in applications. Consider the problem of long-term care for cardiac patients. Electrocardiograms (ECGs) are recorded periodically, often over decades and need to be stored for comparison and assessment of disease progression. Heartbeats arise from electrical signals occuring at frequencies of around Hz (cycles/second). A “single-lead” ECG to detect heart arrhythmia can require s recording time, so a vector representation would require components, ,
| (4) |
where component is the voltage recorded at time , and is the sampling time interval.
The linear combination (4) seems a natural way to organize recorded data, but is it the most insightful? Recall the inclined plane example in which forces seemed to be naturally described in a Cartesian system consisting of the horizontal and vertical directions, yet a more insightful description was seen to correspond to normal and tangential directions. Might there be an alternative linear combination, say
| (5) |
that would represent the ECG in a more meaningful manner? The vectors entering into the linear combination are, as usual, organized into a matrix
such that the ECG is obtained through a matrix-vector product . In particular, in this alternative description, could a smaller number of components suffice for capturing the essence of the ECG? Select the first components by defining
| (6) |
The two-norm of the vectors' difference is the error incurred by keeping only components. If is close to then should be small, and if is much smaller than , a compressed version of the ECG is obtained.
At first sight, the representations (5,6) might seem more costly than (4) since not only do the scaling factors or have to be stored, but also the components of also. This difficulty is eliminated if is obtained by some simple rule, much as can be specified by any one of a number of procedures.
Within the algebraic structure of a vector space there is an identity element with respect to the operation of scaling the vector ,
Analogously, the identity matrix acts as an identity element with respect to matrix vector multiplication
Since matrix-matrix multiplication is simply successive matrix-vector multiplications,
the identity matrix is an identity element for matrix multiplication
Computer storage of the identity matrix might naively seem to require locations, one for every component, but its remarkable structure implies specification only of a single number, the size of . The identity matrix can then be reconstructed as needed through a variety of procedures.
In Julia I is a predefined operator from which the full identity matrix can be reconstructed if needed
∴ |
m=3; Matrix(1.0I,m,m) |
(7)
In terms of components
where is known as Kronecker-delta and is readily transcribed in Julia.
∴ |
δ(i,j) = if i==j return 1 else return 0 end; |
∴ |
Id(m) = [δ(i,j) for i in 1:m, j=1:m]; Id(3) |
(8)
∴ |
Another construction is by circular shifts of the column vector .
∴ |
e1T(m) = [1; zeros(m-1,1)]; e1T(3) |
(9)
∴ |
ekT(m,k) = circshift(e1T(m),k); [ekT(3,0) ekT(3,1) ekT(3,2)] |
(10)
The diagonal structure of also defines a reconstruction.
∴ |
Diagonal(ones(3,3)) |
(11)
∴ |
A conceptually different reconstruction of when uses block matrix operations and builds up larger matrices from smaller ones. This technique is quite instructive in that it:
introduces the concept of an outer product that can be compared to inner products;
introduces the concept of recursive definition.
Since larger versions of the identity matrix will be obtained from smaller ones, a notation to specify the matrix size is needed. Let denote the identity matrix of size with . Start from , in which case , also define
The next matrix in this sequence would be in which a block structure can be identified
The scaling coefficients applied to each block are recognized to be itself. This suggest that the next matrix in the sequence could be obtained as
It is useful to introduce a notation for these operations: .
Recall that the inner product of is the scalar , and one can think of an inner product as “reducing the dimensions of its factors”. In contrast the exterior product “increases the dimensions of its factors”. An example of the exterior product has already been met, namely the projection matrix along direction of unit norm ()
Using the exterior product definition the matrix is defined in terms of previous terms in the sequence as
Such definitions based upon previous terms are said to be recursive.
An alternative to specifying the signal as the linear combination is now constructed by a different recursion procedure. As in the identity matrix case let and start from , with . For the next term choose however
and define in general
Julia can be extended to include definitions of the above Hadamard matrices.
∴ |
using Hadamard |
∴ |
H0=hadamard(2^0) |
(12)
∴ |
H1=hadamard(2^1) |
(13)
∴ |
H2=hadamard(2^2) |
(14)
∴ |
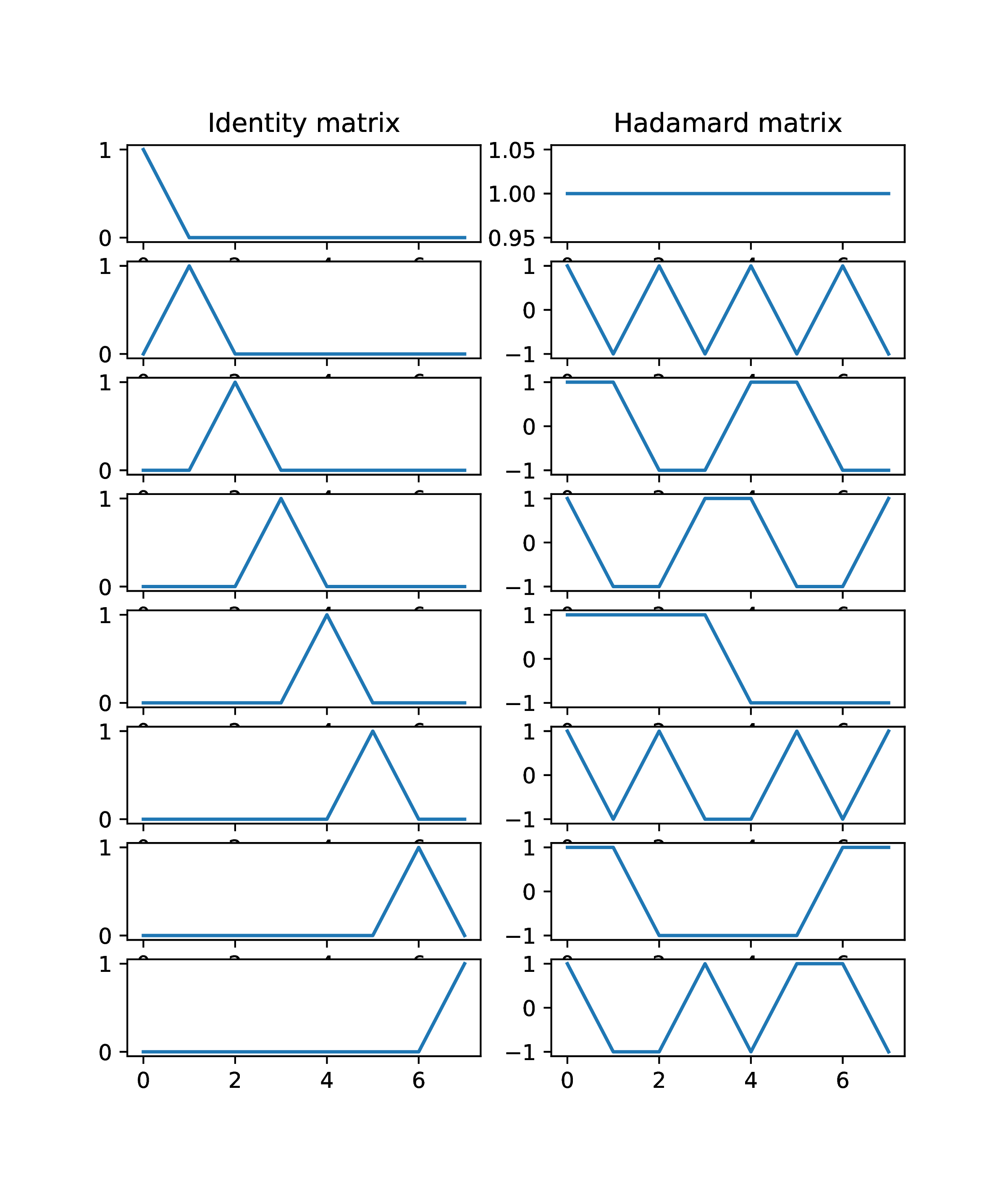
The column vectors of the identity matrix are mutually orthogonal as expressed by
The Hadamard matrices have similar behavior in that
and thus be seen to have orthogonal columns.
∴ |
H2'*H2 |
(15)
∴ |
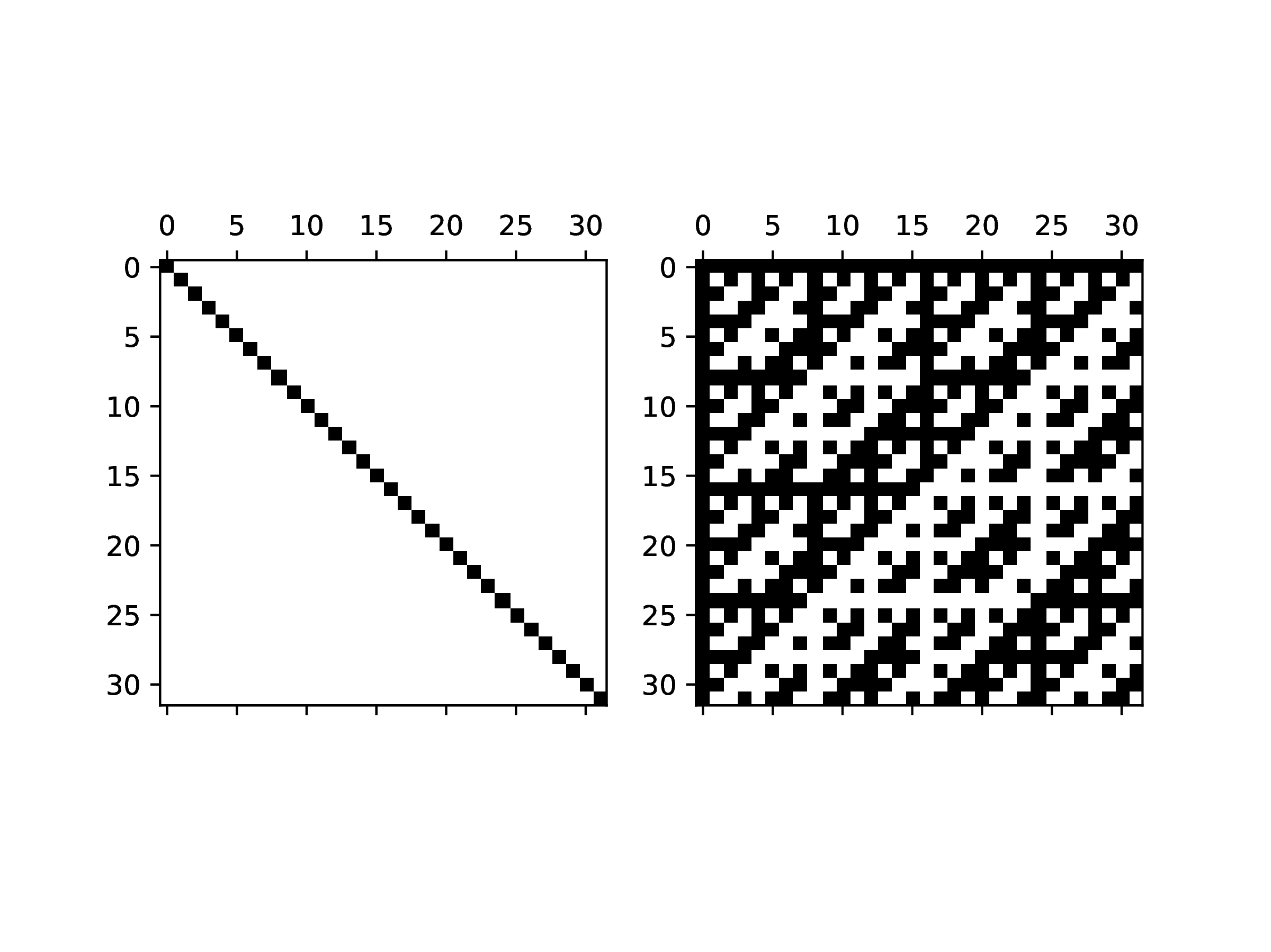
The structure of Hadamard matrices allows a reconstruction from small cases just as simple as that of the identity matrix, but the components of a Hadamard matrix are quite different. Rather than display of the components a graphical visualization is insightful. The spy(A) function displays a plot of the non-zero components of a matrix
∴ |
q=5; m=2^q; Iq=Matrix(1.0I,m,m); Hq=hadamard(m); |
∴ |
clf(); subplot(1,2,1); spy(Iq); subplot(1,2,2); spy(Hq.+1); |
∴ |
cd(homedir()*"/courses/MATH347DS/images"); savefig("L03Fig01.eps"); |
∴ |
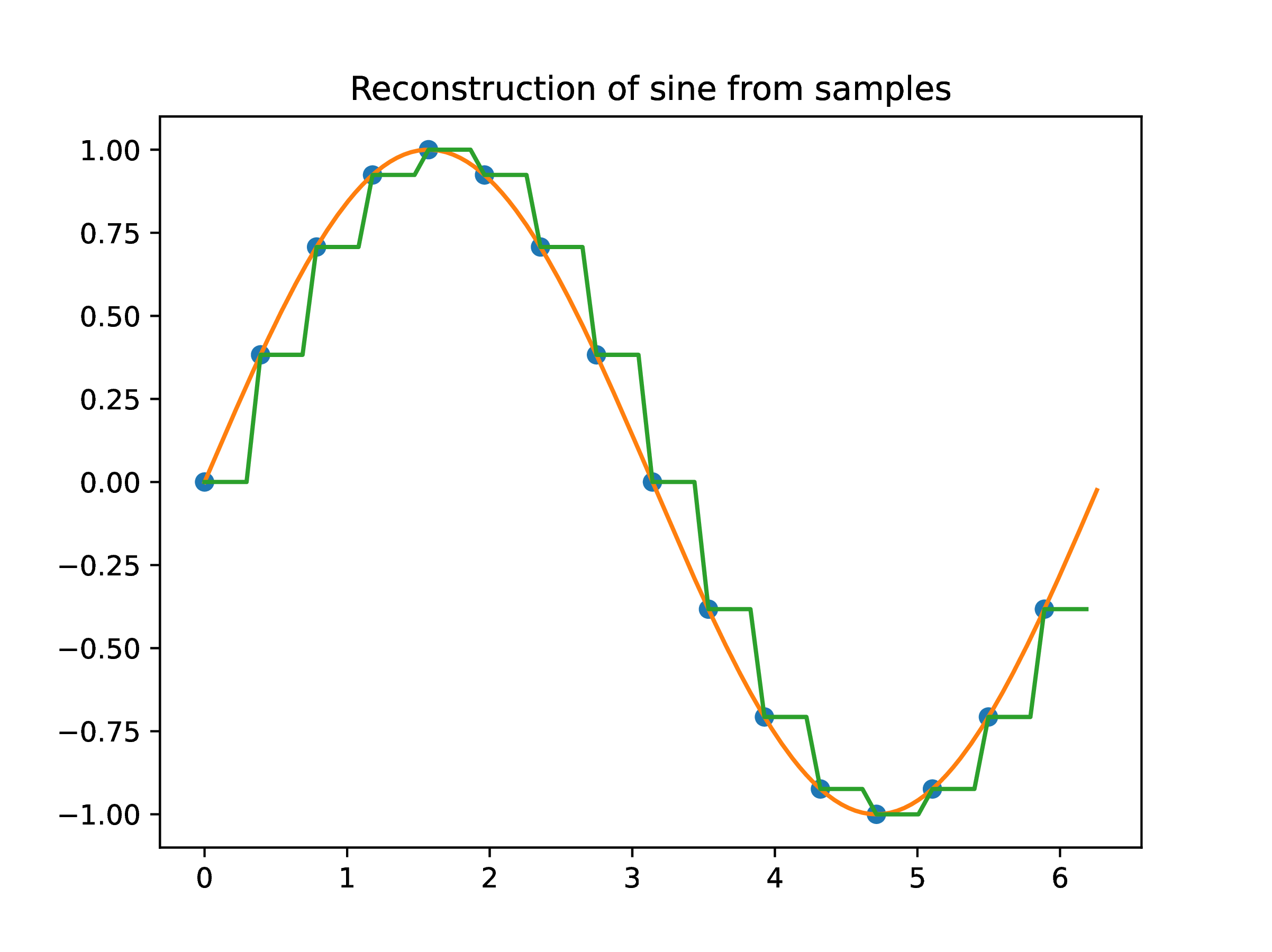
The behavior of the column vectors of and is instructive. Denote by the ECG recording that would be obtained measurements were carried out for all . This is obviously impossible since it would require an infinite number of measurements. In practice, only the values are recorded for , which is a sample of the infinite set of the possible values. The sample set values are organized into the vector . Function values for can be reconstructed through some assumption, for instance that
The above states that remains constant from to . A simple example when illustrates the approach.
∴ |
T=2*pi; n=16; δt=T/n; t=(0:n-1)*δt; b=sin.(t); |
∴ |
m=n^2; δts=T/m; ts=(0:m-1)*δts; s=sin.(ts); |
∴ |
p=4*n; δtw=T/p; tw=(0:p-1)*δtw; w=reshape((b.*[1 1 1 1])',(1,p))'; |
∴ |
figure(3); clf(); plot(t,b,"o",ts,s,tw,w); |
∴ |
title("Reconstruction of sine from samples"); |
∴ |
savefig("L04Fig02.eps"); |
∴ |
The reconstruction exhibits steps at which the function value changes. The column vectors of are well suited for such reconstructions.
∴ |
n=8; In=Matrix(1.0I,n,n); Hn=hadamard(n); |
∴ |
figure(5); clf(); |
∴ |
for j=1:n subplot(8,2,2*j-1); plot(In[:,j]) subplot(8,2,2*j); plot(Hn[:,j]) end |
∴ |
title("Column vectors of I"); |
∴ |
subplot(2,1,2); |
∴ |
for j=1:n plot(Hn[:,j]) end |
∴ |
subplot(8,2,1); title("Identity matrix"); |
∴ |
subplot(8,2,2); title("Hadamard matrix"); |
∴ |
savefig("L04Fig03.eps"); |
∴ |
are truncated? The scaling coefficients of the Hadamard linear combination are readily found
Consider to be the truncation of to terms
Due to the choice of the significance of the components the above simply drops ECG recording times for . The truncation of the Hadamard linear combination
behaves quite differently.
∴ |
using MAT |
∴ |
DataFileName = homedir()*"/courses/MATH347DS/data/ecg/ECGData.mat"; |
∴ |
DataFile = matopen(DataFileName,"r"); |
∴ |
dict = read(DataFile,"ECGData"); |
∴ |
data = dict["Data"]'; |
∴ |
size(data) |
(16)
∴ |
q=12; m=2^q; k=15; b=data[1:m,k]; |
∴ |
Iq=Matrix(1.0I,m,m); Hq=hadamard(m); c=(1/m)*transpose(Hq)*b; |
∴ |
n=2^10; u=Iq[:,1:n]*b[1:n]; v=Hq[:,1:n]*c[1:n]; |
∴ |
figure(1); clf(); subplot(3,1,1); plot(b); |
∴ |
subplot(3,1,2); plot(u); |
∴ |
subplot(3,1,3); plot(v); |
∴ |
cd(homedir()*"/courses/MATH347DS/images"); savefig("L03Fig02.eps"); |
∴ |
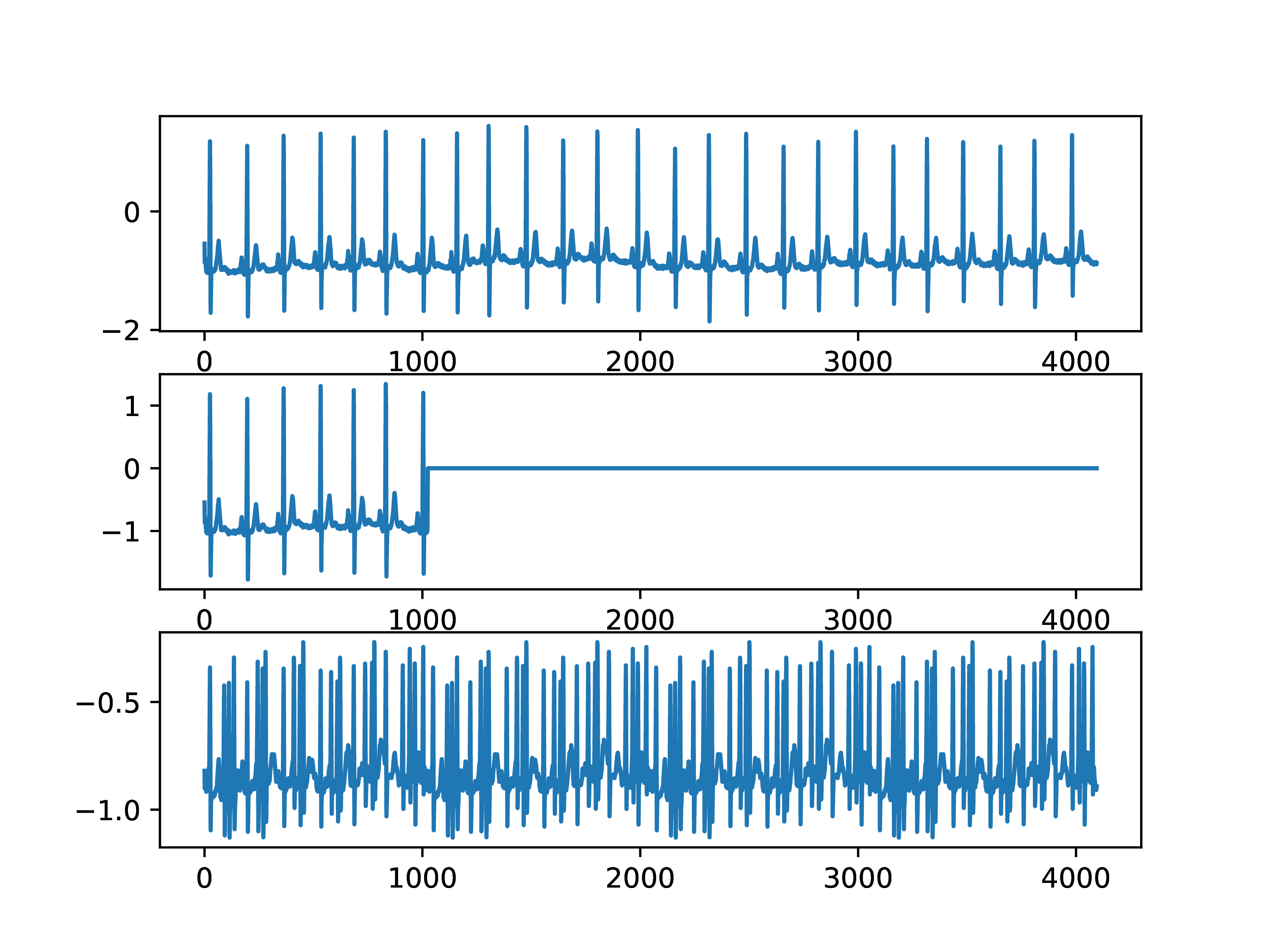 |
Neither of the truncated linear combinations seems particularly useful. Truncation of the -based linear combination cuts off part of the signal, while that of the -based linear combination introduces heart pulses not present in the original signal. The problem is the significance given to the ordering of the vectors into the linear combination. Consider first truncation of to obtain . Rather than cutting off part of the signal, an alternative data compression is to use a larger time sample, say 4 instead of , a process known as down-sampling,
∴ |
w=fwht(b); |
∴ |
figure(6); clf(); plot(c,"."); |
∴ |
plot(w,"."); |
∴ |