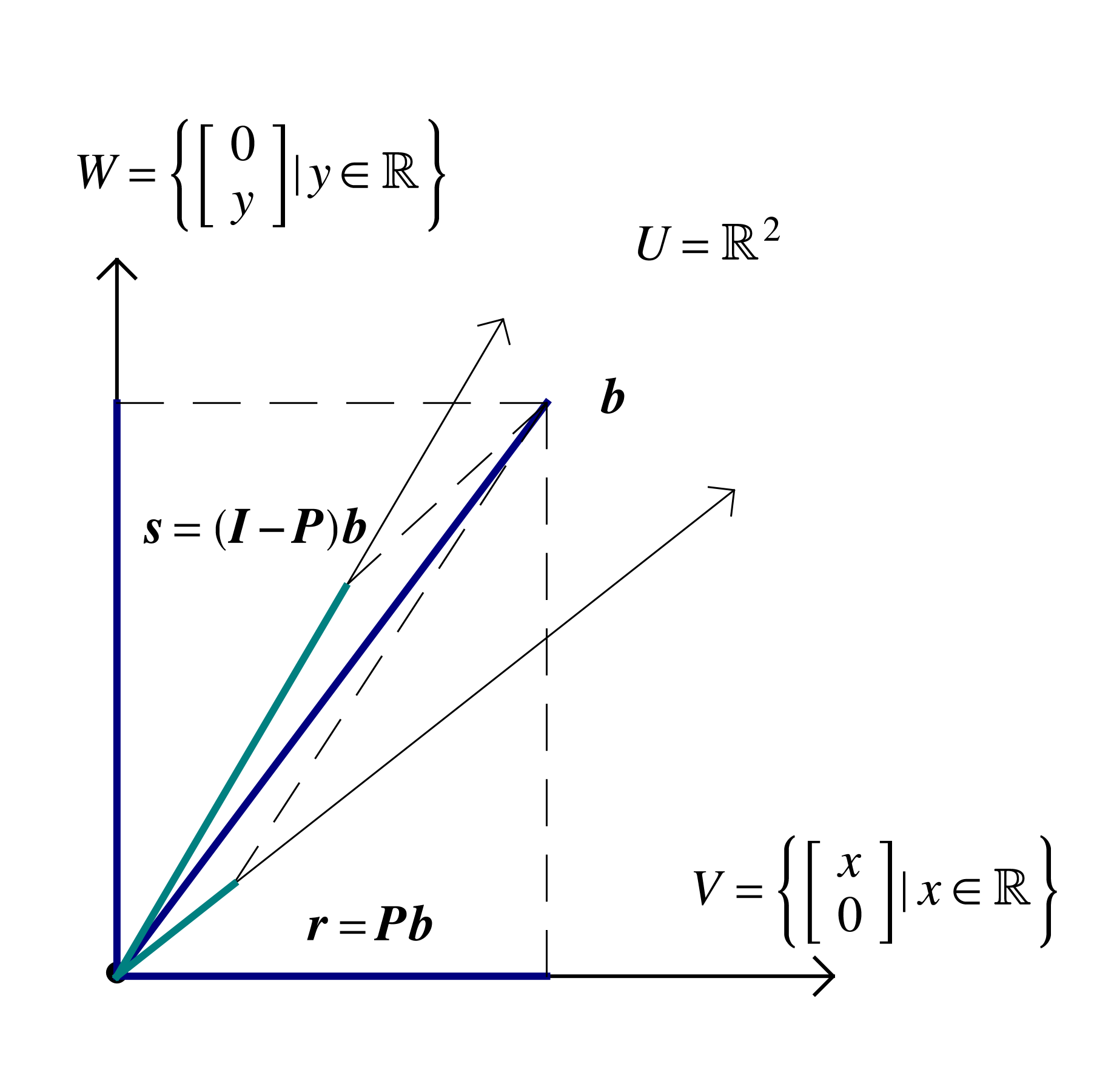
Consider a partition of a vector space into orthogonal subspaces , , , typically , , , , . If is a basis for and is a basis for W, then is a basis for . Even though the matrices are not necessarily square, they are said to be orthonormal when all columns are of unit norm and orthogonal to one another. In this case computation of the matrix product leads to the formation of the identity matrix within
Similarly, . Whereas for the square orthogonal matrix multiplication both on the left and the right by its transpose leads to the formation of the identity matrix
the same operations applied to rectangular orthogonal matrices lead to different results
A simple example is provided by taking , the first columns of the identity matrix in which case
Applying to some vector leads to a vector whose first components are those of , and the remaining are zero. The subtraction leads to a new vector that has the first components equal to zero, and the remaining the same as those of . Such operations are referred to as projections, and for correspond to projection onto the span.
Returning to the general case, the orthogonal matrices , , are associated with linear mappings , , . The mapping gives the components in the basis of a vector whose components in the basis are . The mappings project a vector onto span, span, respectively. When are orthogonal matrices the projections are also orthogonal . Projection can also be carried out onto nonorthogonal spanning sets, but the process is fraught with possible error, especially when the angle between basis vectors is small, and will be avoided henceforth. Notice that projection of a vector already in the spanning set simply returns the same vector, which leads to a general definition.
Orthogonal projections onto the column space of an orthonormal matrix are of great practical utility, and satisfy the above definition
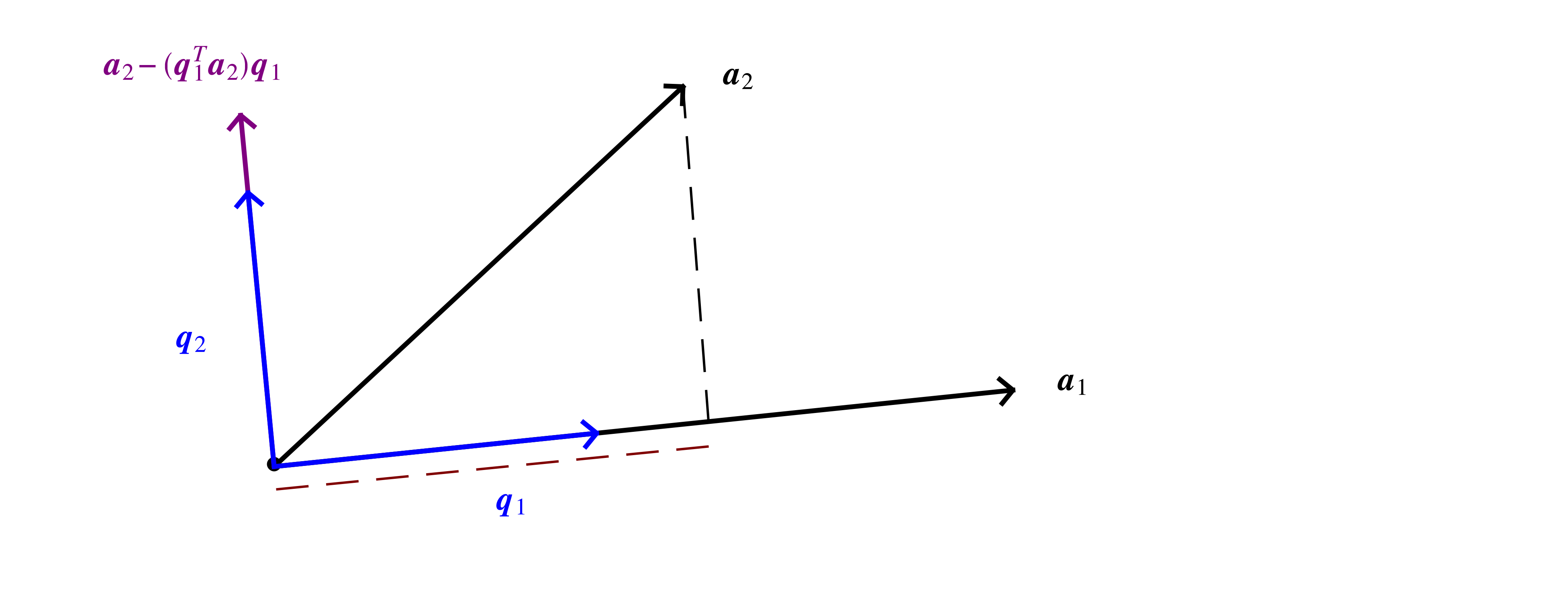
Orthonormal vector sets are of the greatest practical utility, leading to the question of whether some such a set can be obtained from an arbitrary set of vectors . This is possible for independent vectors, through what is known as the Gram-Schmidt algorithm
Start with an arbitrary direction
Divide by its norm to obtain a unit-norm vector
Choose another direction
Subtract off its component along previous direction(s)
Divide by norm
Repeat the above
The above geometrical description can be expressed in terms of matrix operations as
equivalent to the system
The system is easily solved by forward substitution resulting in what is known as the (modified) Gram-Schmidt algorithm, transcribed below both in pseudo-code and in Julia.
Algorithm (Gram-Schmidt) Given vectors Initialize ,..,, for to
if break;
for +1 to ; end end return |
|
The input matrix might have linearly dependent columns in which case for some , and the if-instruction interrupts the algorithm. The Gram-Schmidt algorithm furnishes a factorization
with an orthonormal matrix and an upper triangular matrix, known as the -factorization. Since the column vectors within were obtained through linear combinations of the column vectors of , . The -factorization is of great utility in solving problems within linear algebra.
A typical situation in applications is that a vector represents a complex object with . A simpler representation of the object is sought through a linear combination , with and , usually (Fig. 1).
The magnitude of the difference between the exact object and the approximation is measured through a norm, and in least squares the 2-norm is adopted. The problem is to minimize the error . This is stated mathematically as
and within the minimal (2-norm) distance is obtained when is orthogonal to . Note that is another type of norm were to be adopted, the orthogonality condition would no longer necessarily hold. For the 2-norm however, the orthogonality condition leads to a straightforward solution of the problem through orthogonal projection:
Find an orthonormal basis for column space of by factorization, .
State that is the projection of , .
State that is within the column space of , .
Set equal the two expressions of , . This is an equality between two linear combinations of the columns of . For orthonormal the scaling coefficients of the two linear combinations must be equal leading to .
Solve the triangular system to find .
The approach to compressing data suggested by calculus concepts is to form the sum of squared differences between and , for example for when carrying out linear regression,
and seek that minimize . The function can be thought of as the height of a surface above the plane, and the gradient is defined as a vector in the direction of steepest slope. When at some point on the surface if the gradient is different from the zero vector , travel in the direction of the gradient would increase the height, and travel in the opposite direction would decrease the height. The minimal value of would be attained when no local travel could decrease the function value, which is known as stationarity condition, stated as . Applying this to determining the coefficients of a linear regression leads to the equations
The above calculations can become tedious, and do not illuminate the geometrical essence of the calculation, which can be brought out by reformulation in terms of a matrix-vector product that highlights the particular linear combination that is sought in a liner regression. Form a vector of errors with components , which for linear regression is . Recognize that is a linear combination of and with coefficients , or in vector form
The norm of the error vector is smallest when is as close as possible to . Since is within the column space of , , the required condition is for to be orthogonal to the column space
The above is known as the normal system, with is the normal matrix. The system can be interpreted as seeking the coordinates in the basis of the vector . An example can be constructed by randomly perturbing a known function to simulate measurement noise and compare to the approximate obtained by solving the normal system.
∴ |
m=100; x=(0:m-1)./m; c0=2; c1=3; yex=c0.+c1*x; y=(yex.+rand(m,1).-0.5); |
∴ |
A=ones(m,2); A[:,2]=x[:]; At=transpose(A); N=At*A; b=At*y; |
∴ |
c = N\b |
(1)
∴ |
Forming the normal system of equations can lead to numerical difficulties, especially when the columns of are close to linear dependence. It is preferable to adopt the general procedure of solving a least squares problem by projection, in which case the above linear regression becomes:
∴ |
QR=qr(A); Q=QR.Q[:,1:2]; R=QR.R[1:2,1:2]; |
∴ |
c = R\(transpose(Q)*y) |
(2)
∴ |
The above procedure can be easily extended to define quadratic or cubic regression, the problem of finding the best polynomials of degree 2 or 3 that fit the data. Quadratic regression is simply accomplished by adding a column to containing the squares of the vector
with the column vector has components for .
∴ |
m=100; x=(0:m-1)./m; c0=2; c1=3; c2=-5; yex=c0.+c1*x.+c2*x.^2; |
∴ |
y=(yex.+rand(m,1).-0.5); |
∴ |
A=ones(m,3); A[:,2]=x[:]; A[:,3]=x[:].^2; QR=qr(A); Q=QR.Q[:,1:3]; R=QR.R[1:3,1:3]; |
∴ |
c = R\(transpose(Q)*y) |
(3)
∴ |