MATH347DS L06: The singular value decomposition
|
Overview
-
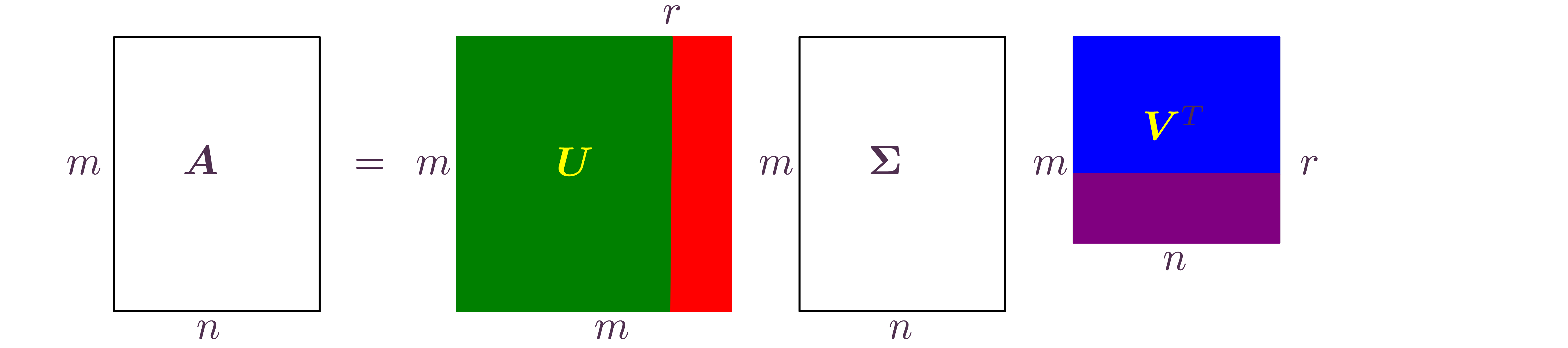
The singular value decomposition (SVD)
-
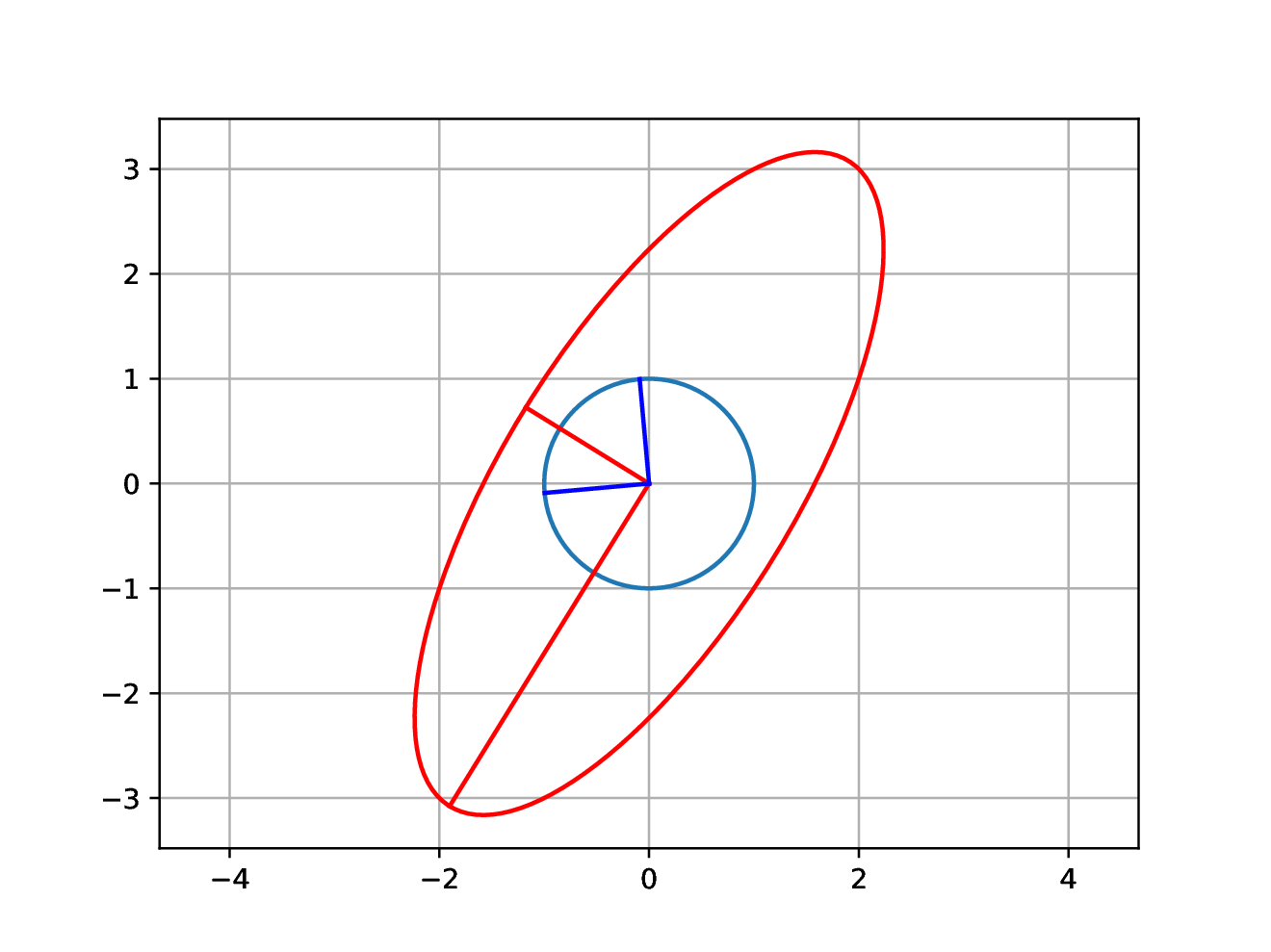
Motivation
-
Theorem
-
-
Another essential diagram: SVD finds orthonormal bases for
-
SVD computation
-
Rank-1 expansion of a matrix
-
Matrix norm
-
SVD in image compression, analysis
-
The pseudo-inverse