1.Rate and order of convergence
Exercise
Exercise
Can you estimate the rate and order of convergence?
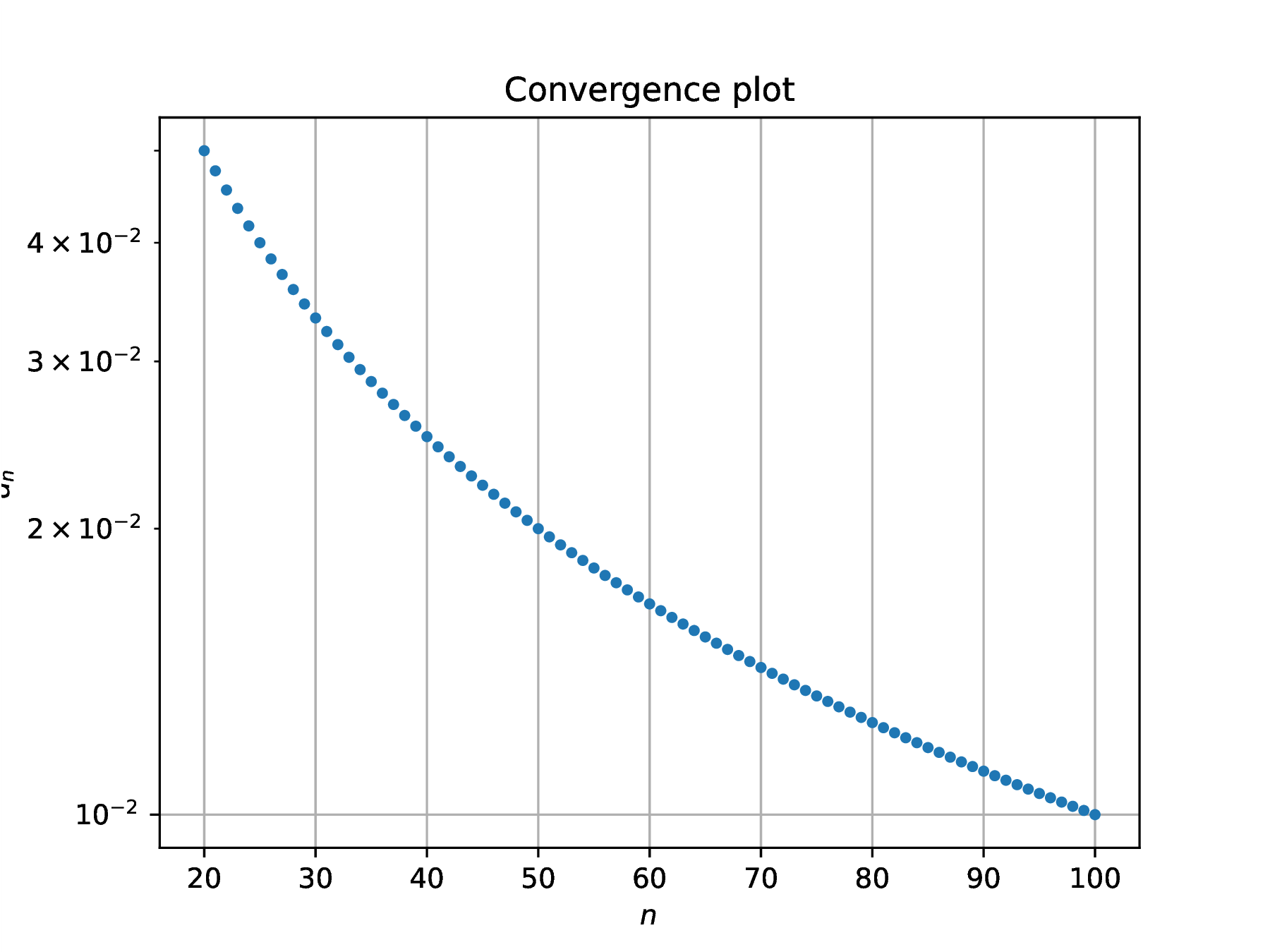
Solution. Since , note that the distance to the limit is simply for . For large , the convergence behavior is given by , leading to upon taking decimal logarithms. In practical computation, is chosen between some upper bound dictated by allowed computational effort and a lower bound needed to start observing convergence
The computed terms allow estimation of by linear regression (least squares fitting) expressed as
The Julia instruction carries out the linear regression (also a feature of Matlab/Octave).
∴ |
M=20; N=100; n=M:N; a=1 ./ log.(n); d=a; lgd=log10.(d); |
∴ |
m=N-M; y=lgd[2:m+1]; A=ones(m,2); A[:,2]=lgd[1:m]; |
∴ |
x=A\y; s=10^x[1]; q=x[2]; [s q] |
(1)
∴ |
From the above, obtain order of convergence (sublinear convergence), and rate of convergence . The convergence plot highlights this sublinear convergence behavior.
∴ |
x=n; y=d; clf(); semilogy(x,y,"."); grid("on"); |
∴ |
xlabel(L"$n$"); ylabel(L"$d_n$"); title("Convergence plot"); |
∴ |
savefig(homedir()*"/courses/MATH661/images/E02Fig01.eps"); |
∴ |

Exercise
Can you estimate the rate and order of convergence?
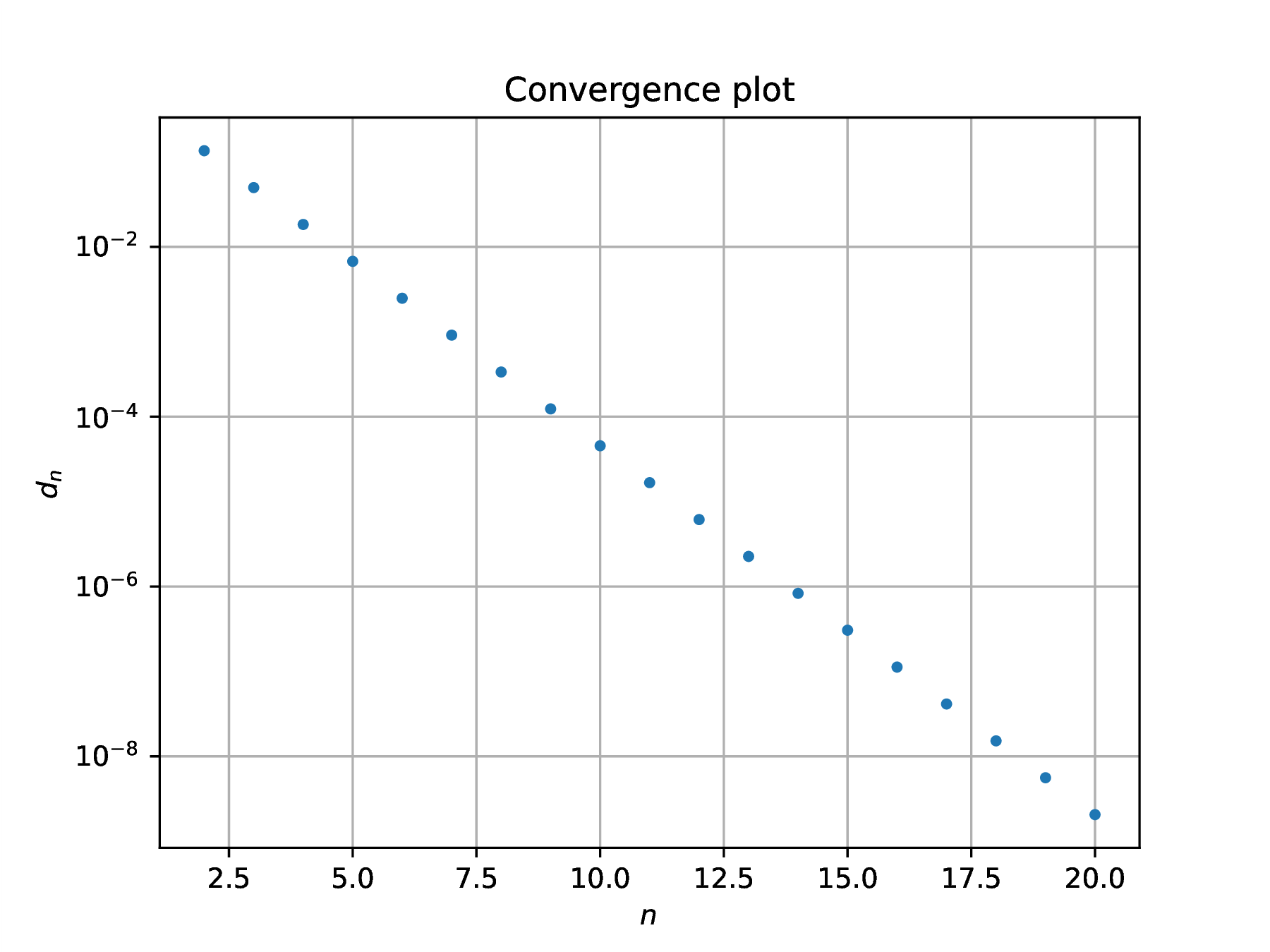
Solution. Again, , hence for . Repeat the above computation for the new sequence choosing lower values for since is expected to converge to zero faster than .
∴ |
M=2; N=20; n=M:N; a=exp.(-n); d=a; lgd=log10.(d); |
∴ |
m=N-M; y=lgd[2:m+1]; A=ones(m,2); A[:,2]=lgd[1:m]; |
∴ |
x=A\y; s=10^x[1]; q=x[2]; [s q] |
(2)
Linear convergence is obtained, , and the rate of convergence . The order of convergence is only slightly better than the previous sequence and faster convergence arise from the marked difference in rate of convergence.
∴ |
x=n; y=d; clf(); semilogy(x,y,"."); grid("on"); |
∴ |
xlabel(L"$n$"); ylabel(L"$d_n$"); title("Convergence plot"); |
∴ |
savefig(homedir()*"/courses/MATH661/images/E02Fig02.eps"); |
∴ |
Exercise