Lecture 4: Linear Combinations
1.Finite-dimensional vector spaces
1.1.Overview
The definition from Table 1 of a vector space reflects everyday
experience with vectors in Euclidean geometry, and it is common to
refer to such vectors by descriptions in a Cartesian coordinate
system. For example, a position vector
within the plane can be referred through the pair of coordinates .
This intuitive understanding can be made precise through the
definition of a vector space , called the real 2-space. Vectors
within are
elements of , meaning that a vector is specified
through two real numbers, .
Addition of two vectors, ,
is defined by addition of
coordinates . Scaling
by scalar is defined by . Similarly, consideration of
position vectors in three-dimensional space leads to the definition of
the , or more generally a real -space , ,
.
| Addition rules for |
|
|
Closure |
|
Associativity |
|
Commutativity |
|
Zero vector |
|
Additive inverse |
| Scaling rules for |
,
|
|
Closure |
|
Distributivity |
|
Distributivity |
|
Composition |
|
Scalar identity |
|
|
Table 1. Vector space properties for arbitrary
|
Note however that there is no mention of coordinates in the definition
of a vector space as can be seen from the list of properties in Table 1.
The intent of such a definition is to highlight that besides position
vectors, many other mathematical objects follow the same rules. As an
example, consider the set of all continuous functions , with function addition defined by the
sum at each argument
, and scaling
by
defined as . Read this
as: “given two continuous functions
and , the function
is defined by stating that its value for argument
is the sum of the two real numbers and ”.
Similarly: “given a continuous function ,
the function
is defined by stating that its value for argument
is the product of the real numbers and
”.
Under such definitions is a vector space, but quite different
from .
Nonetheless, the fact that both
and are vector
spaces can be used to obtain insight into the behavior of continuous
functions from Euclidean vectors, and vice versa. This correspondence
principle between discrete and continuous formulations is a recurring
theme in scientific computation.
1.2.Real vector space
Column vectors.
Since the real spaces play such an important role in
themselves and as a guide to other vector spaces, familiarity with
vector operations in
is necessary to fully appreciate the utility of linear algebra to a
wide range of applications. Following the usage in geometry and
physics, the real numbers that specify
a vector
are called the components of .
The one-to-one correspondence between a vector and its components
, is by convention taken to define an
equality relationship,
with the components arranged vertically and enclosed in square brackets.
Given two vectors ,
and a scalar ,
vector addition and scaling are defined in
by real number addition and multiplication of components
|
(2) |
∴ |
u=[1; 2; 3]; v=[-1; -2; -3]; [u v] |
The vector space
is defined using the real numbers as the set of scalars, and
constructing vectors by grouping together
scalars, but this approach can be extended to any set of scalars , leading to the definition of the vector spaces
. These will often be referred to as
-vector space of scalars,
signifying that the set of vectors is .
To aid in visual recognition of vectors, the following notation
conventions are introduced:
-
vectors are denoted by lower-case bold Latin letters: ;
-
scalars are denoted by normal face Latin or Greek letters: ;
-
the components of a vector are denoted by the corresponding normal
face with subscripts as in equation (1);
-
related sets of vectors are denoted by indexed bold Latin letters:
.
Row vectors.
Instead of the vertical placement or components into one
column, the components of could have been placed horizontally
in one row , that contains the same data,
differently organized. By convention vertical placement of vector
components is the preferred organization, and
shall denote a column vector henceforth. A transpose
operation denoted by a superscript is
introduced to relate the two representations
and is the
notation used to denote a row vector.
In Julia, horizontal placement of successive
components in a row is denoted by a space.
Compatible vectors.
Addition of real vectors
defines another vector .
The components of are the sums of
the corresponding components of and
, ,
for .
Addition of vectors with different number of components is not
defined, and attempting to add such vectors produces an error. Such
vectors with different number of components are called
incompatible, while vectors with the same number of
components are said to be compatible. Scaling of
by defines a vector ,
whose components are ,
for .
1.3.Working with vectors
Ranges.
The vectors used in applications usually have a large number of
components, ,
and it is important to become proficient in their manipulation.
Previous examples defined vectors by explicit listing of their components. This is impractical for large
, and support is provided for automated
generation for often-encountered situations. First, observe that Table
1 mentions one distinguished vector, the zero element that is a member
of any vector space .
The zero vector of a real vector space
is a column vector with components, all
of which are zero, and a mathematical convention for specifying this
vector is .
This notation specifies that transpose of the zero vector is the row
vector with zero components, also
written through explicit indexing of each component as ,
for .
Keep in mind that the zero vector
and the zero scalar are different
mathematical objects.
The ellipsis symbol in the mathematical notation is transcribed in Julia
by the notion of a range, with 1:m denoting all the
integers starting from to ,
organized as a row vector. The notation is extended to allow for strides
different from one, and the mathematical ellipsis
is denoted as m:-1:1. In general r:s:t
denotes the set of numbers with ,
and
real numbers and a natural number, ,
. If
there is no natural number such that
,
an empty vector with no components is returned.
2.Linear combinations
2.1.Linear combination as a matrix-vector
product
The expression
expresses the idea of scaling vectors within a set and subsequent
addition to form a new vector . The
matrix groups these vectors
together in a single entity, and the scaling factors are the components
of the vector . To bring all these
concepts together it is natural to consider the notation
UniformScaling{Bool}(true)
|
(7) |
|
(8) |
as a generalization of the scalar expression .
It is clear what the operation
should signify: it should capture the vector scaling and subsequent
vector addition .
A specific meaning is now ascribed to
by identifying two definitions to one another.
Linear combination.
Repeateadly stating “vector scaling and subsequent vector
addition” is unwieldy, so a special term is introduced for some
given set of vectors .
Definition. (Linear
Combination) . The linear
combination of vectors
with scalars
in vector space is the vector
Matrix-vector product.
Similar to the grouping of unit vectors
into the identity matrix , a more
concise way of referring to arbitrary vectors
from the same vector space is the matrix . Combining these
observations leads to the definition of a matrix-vector product.
Definition. (Matrix-Vector
Product) . In the vector space , the product of matrix composed of columns
with the vector
whose components are scalars
is the linear combination
2.2.Linear algebra problem examples
Linear combinations in .
Consider a simple example that leads to a common linear algebra
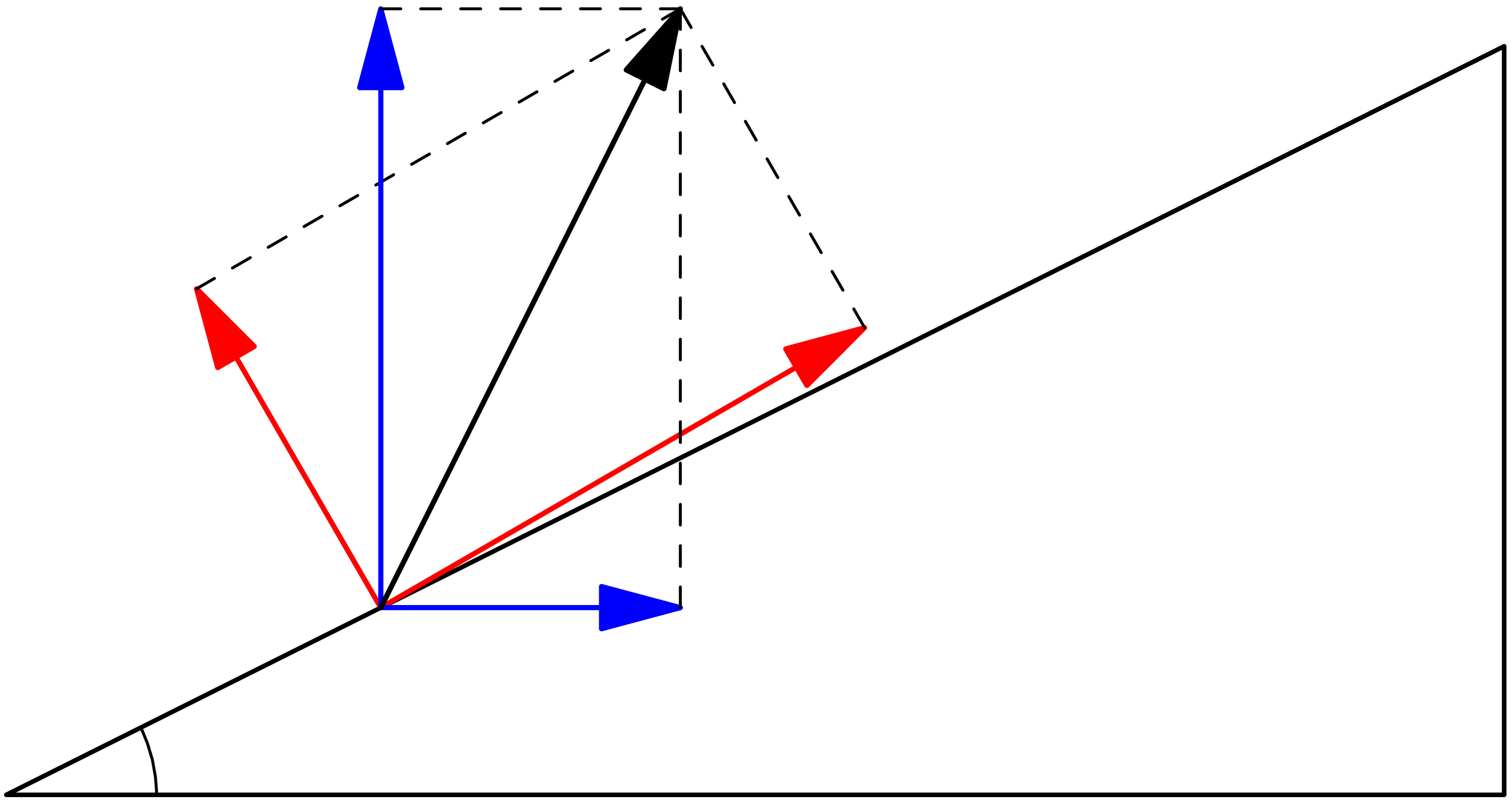
problem: decomposition of forces in the plane along two directions.
Suppose a force is given in terms of components along the Cartesian
-axes,
,
as expressed by the matrix-vector multiplication
Note that the same force could be obtained by linear combination of
other vectors, for instance the normal and tangential components of
the force applied on an inclined plane with angle
,
,
as in Figure
1. This defines an alternate reference
system for the problem. The unit vectors along these directions are
∴ |
θ=π/6.; c=cos(θ); s=sin(θ); t=[c; s]; n=[-s; c]; |
and can be combined into a matrix . The value of the
components are the scaling factors and can be combined
into a vector . The
same force must result irrespective of whether its components are given
along the Cartesian axes or the inclined plane directions leading to the
equality
Interpret equation (9) to state that the vector could be obtained either as a linear
combination of , ,
or as a linear combination of the columns of ,
.
Of course the simpler description seems to be
for which the components are already known. But this is only due to an
arbitrary choice made by a human observer to define the force in terms
of horizontal and vertical components. The problem itself suggests that
the tangential and normal components are more relevant; for instance a
friction force would be evaluated as a scaling of the normal force.
The components of
in this more natural reference system are not known, but can be
determined by solving the vector equality ,
known as a linear system of equations, implemented in
many programming environments (Julia, Matlab, Octave) through the
backslash operator x=A\b.
|
(11) |
|
(12) |
|
|
|
Figure 1. Alternative decompositions of
force on inclined plane.
|
|
Linear combinations in and .
Linear combinations in a real space can
suggest properties or approximations of more complex objects such as
continuous functions. Let denote the vector space of continuous
functions that are periodic on the interval , . Recall that vector addition is
defined by , and scaling
by , for ,
.
Familiar functions within this vector space are ,
with ,
and these can be recognized to intrinsically represent periodicity on
, a role analogous to the normal and
tangential directions in the inclined plane example. Define now another
periodic function by repeating the values
from the interval on all intervals , for .
The function is not given in terms of the
“naturally” periodic functions ,
, but could it thus be expressed? This
can be stated as seeking a linear combination
as studied in Fourier analysis. The coefficients
could be determined from an analytical formula involving calculus
operations
but we'll seek an approximation using a linear combination of terms
Organize this as a matrix vector product ,
with
The idea is to sample the column vectors of at the
components of the vector ,
,
,
.
Let , and , denote
the so-sampled
functions leading to the definition of a vector
and a matrix .
There are coefficients available to scale
the column vectors of , and has
components. For
it is generally not possible to find
such that
would exactly equal , but as seen later
the condition to be as close as possible to
leads to a well defined solution procedure. This is known as a least
squares problem and is automatically applied in the x=A\b
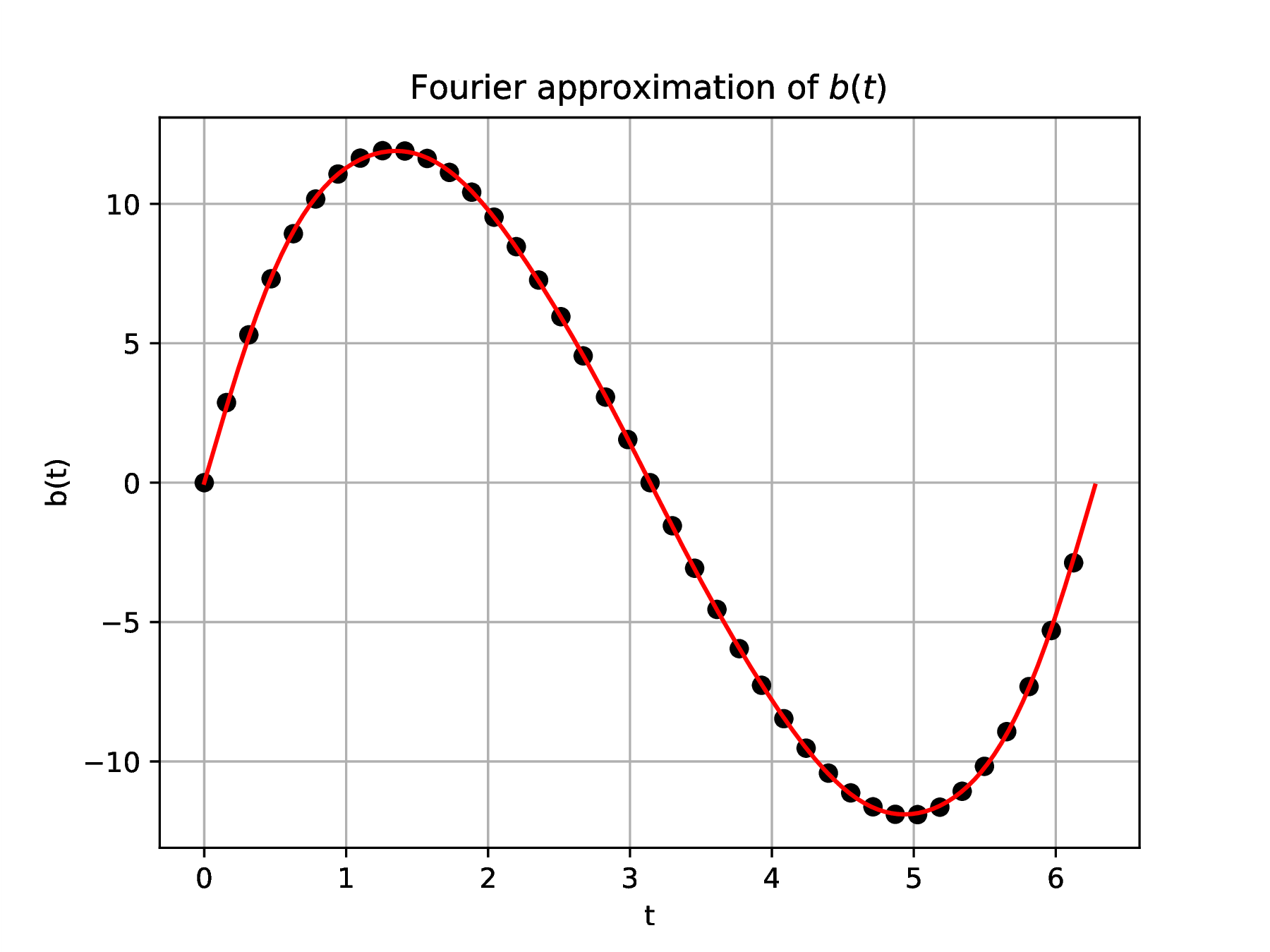
instruction when the matrix A is not square. As seen in
the following numerical experiment and Figure 2, the
approximation is excellent and the information conveyed by
samples of is now much more efficiently stored in
the form chosen for the columns of and
the
scaling coefficients that are the components of .
 |
|
Figure 2. Comparison of least squares
approximation (red line) with samples (black dots) of exact
function
|
∴ |
m=1000; h=2*π/m; j=1:m; |
∴ |
for k=2:n
global A
A = [A sin.(k*t)]
end; |
∴ |
bt=t.*(π.-t).*(2*π.-t); |
∴ |
s=25; i=1:s:m; ts=t[i]; bs=bt[i]; |
∴ |
clf(); plot(ts,bs,"ok",t,b,"r"); |
∴ |
xlabel("t"); ylabel("b(t)"); grid("on") |
∴ |
title("Fourier approximation of \$b(t)\$"); |
∴ |
cd(homedir()*"/courses/MATH661/images"); |
∴ |
savefig("L04Fig02.eps"); |
|
|
Summary.
-
A widely used framework for constructing additive approximations is
the vector space algebraic space structure in which scaling and
addition operations are defined
-
In a vector space linear combinations are used to construct more
complicated objects from simpler ones