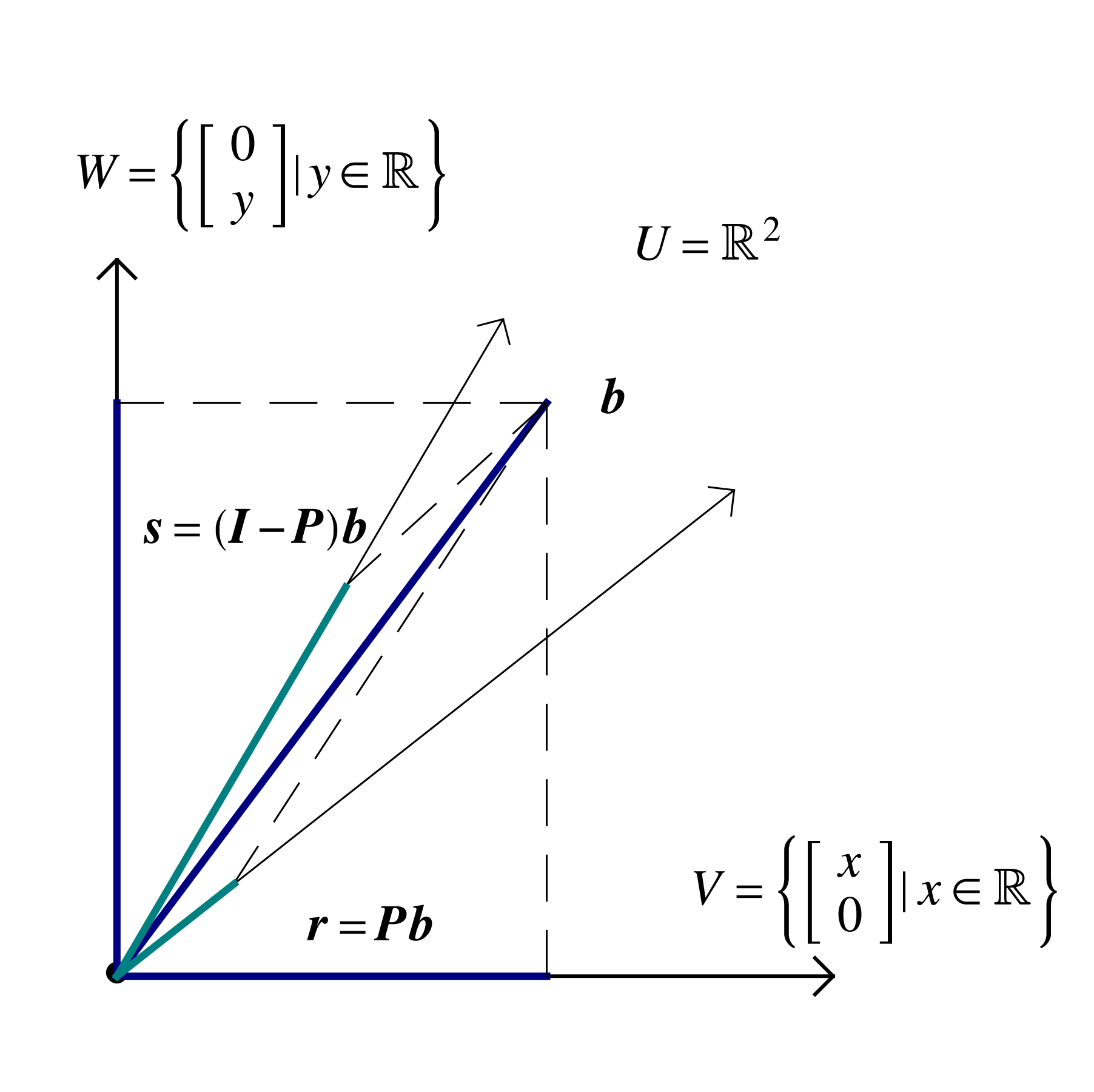 |
A typical scenario in many sciences is acquisition of numbers to describe some object that is understood to actually require only parameters. For example, voltage measurements of an alternating current could readily be reduced to three parameters, the amplitude, phase and frequency . Very often a simple first-degree polynomial approximation is sought for a large data set . All of these are instances of data compression, a problem that can be solved in a linear algebra framework.
Consider a partition of a vector space into orthogonal subspaces , , . Within the typical scenario described above , , , , . If is a basis for and is a basis for W, then is a basis for . Even though the matrices are not necessarily square, they are said to be orthonormal, in the sense that all columns are of unit norm and orthogonal to one another. Computation of the matrix product leads to the formation of the identity matrix within
Similarly, . Whereas for the square orthogonal matrix multiplication both on the left and the right by its transpose leads to the formation of the identity matrix
the same operations applied to rectangular orthonormal matrices lead to different results
A simple example is provided by taking , the first columns of the identity matrix in which case
Applying to some vector leads to a vector whose first components are those of , and the remaining are zero. The subtraction leads to a new vector that has the first components equal to zero, and the remaining the same as those of . Such operations are referred to as projections, and for correspond to projection onto the span.
|
Returning to the general case, the orthogonal matrices , , are associated with linear mappings , , . The mapping gives the components in the basis of a vector whose components in the basis are . The mappings project a vector onto span, span, respectively. When are orthogonal matrices the projections are also orthogonal . Projection can also be carried out onto nonorthogonal spanning sets, but the process is fraught with possible error, especially when the angle between basis vectors is small, and will be avoided henceforth.
Notice that projection of a vector already in the spanning set simply returns the same vector, which leads to a general definition.
Orthonormal vector sets are of the greatest practical utility, leading to the question of whether some such a set can be obtained from an arbitrary set of vectors . This is possible for independent vectors, through what is known as the Gram-Schmidt algorithm
Start with an arbitrary direction
Divide by its norm to obtain a unit-norm vector
Choose another direction
Subtract off its component along previous direction(s)
Divide by norm
Repeat the above
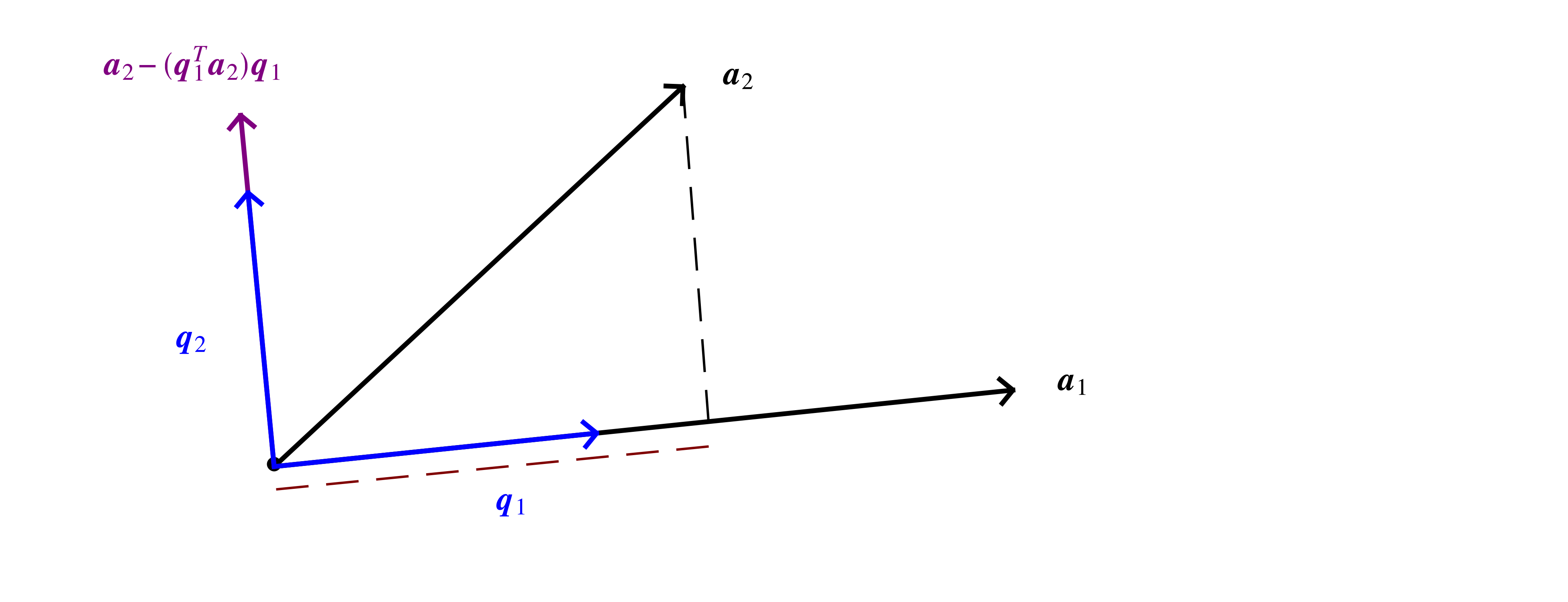
The above geometrical description can be expressed in terms of matrix operations as
equivalent to the system
The system is easily solved by forward substitution resulting in what is known as the (modified) Gram-Schmidt algorithm, transcribed below both in pseudo-code and in Julia.
Algorithm (Gram-Schmidt) Given vectors Initialize ,..,, for to
if break;
for +1 to ; end end return |
|
Note that the normalization condition is satisifed by two values , so results from the above implementation might give orthogonal vectors of different orientations than those returned by the Octave qr function. The implementation provided by computational packages such as Octave contain many refinements of the basic algorithm and it's usually preferable to use these in application
By analogy to arithmetic and polynomial algebra, the Gram-Schmidt algorithm furnishes a factorization
with with orthonormal columns and an upper triangular matrix, known as the -factorization. Since the column vectors within were obtained through linear combinations of the column vectors of we have
The -factorization can be used to solve basic problems within linear algebra.
Recall that when given a vector , an implicit basis is assumed, the canonical basis given by the column vectors of the identity matrix . The coordinates in another basis can be found by solving the equation
by an intermediate change of coordinates to the orthogonal basis . Since the basis is orthogonal the relation holds, and changes of coordinates from to , are easily computed . Since matrix multiplication is associative
the relations are obtained, stating that also contains the coordinates of in the basis . The three steps are:
Compute the -factorization, ;
Find the coordinates of in the orthogonal basis , ;
Find the coordinates of in basis , .
Since is upper-triangular,
the coordinates of in the basis are easily found by back substitution.
Algorithm (Back substitution) Given upper-triangular, vectors for down to if break;
for -1 down to
end end return |
|
The above operations are carried out in the background by the backslash operation A\b to solve A*x=b, inspired by the scalar mnemonic .
The above approch for the real vector space can be used to determine orthogonal bases for any other vector space by appropriate modification of the scalar product. For example, within the space of smooth functions that can differentiated an arbitrary number of times, the Taylor series
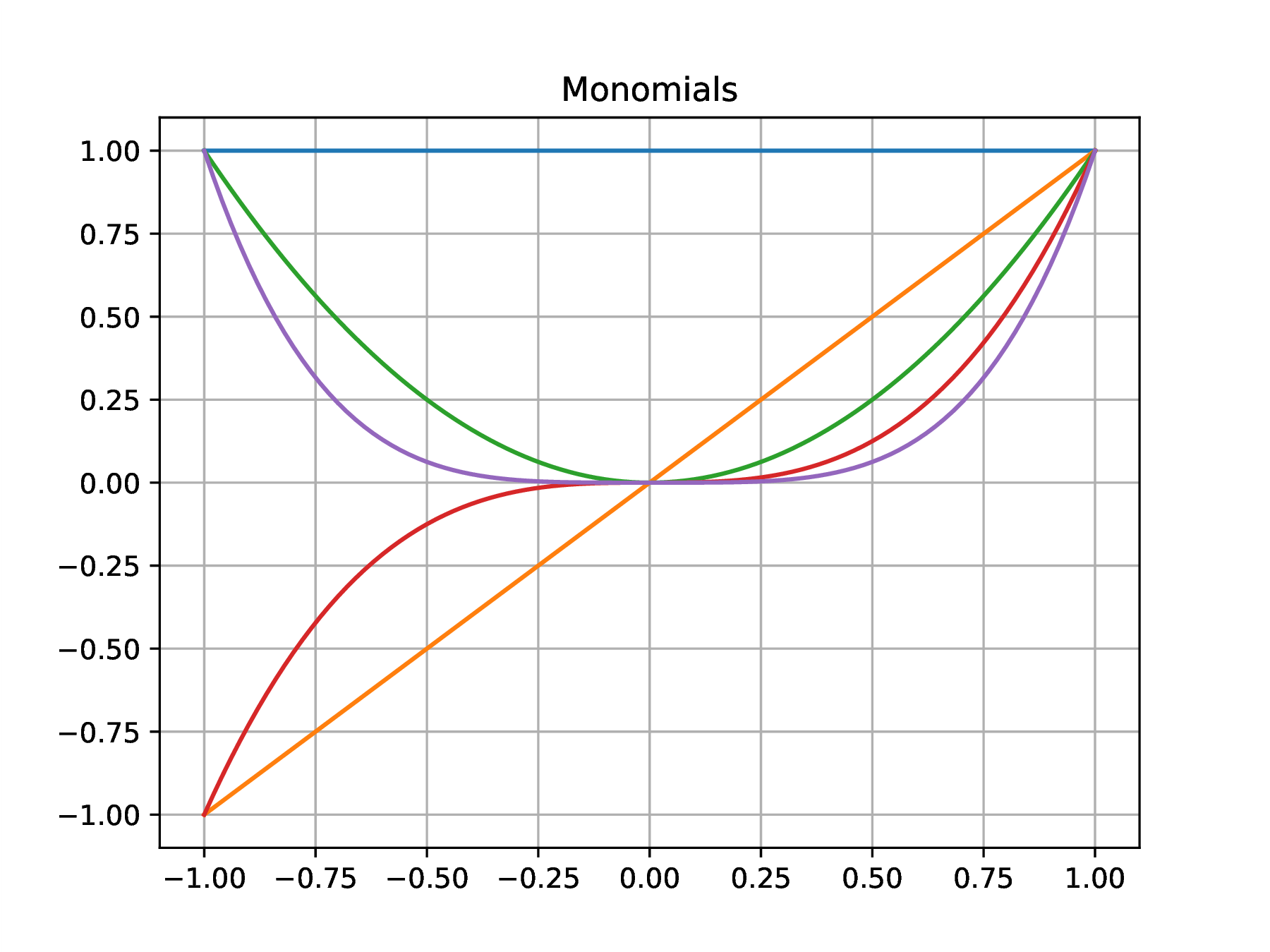
is seen to be a linear combination of the monomial basis with scaling coefficients . The scalar product
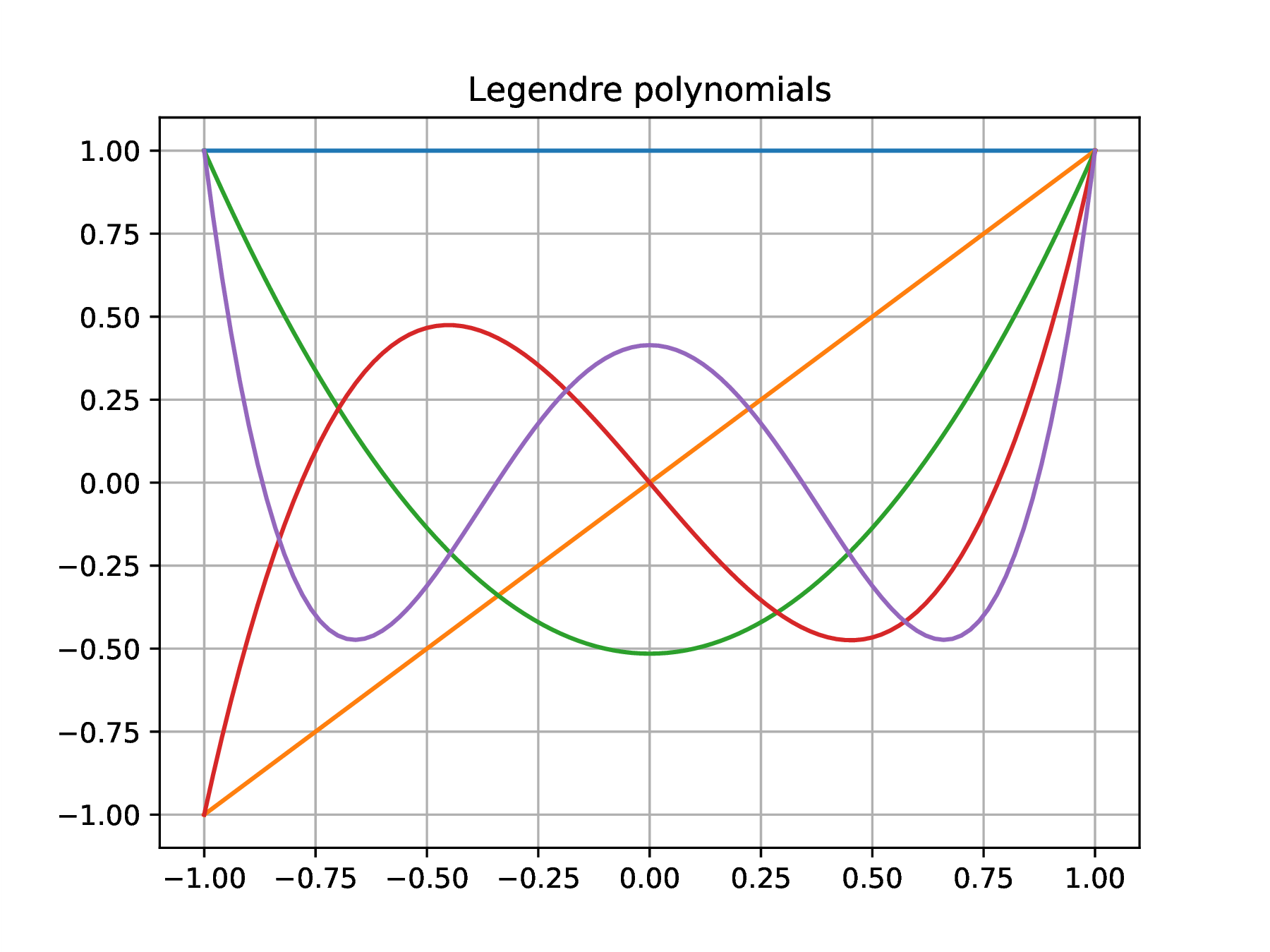
can be seen as the extension to the continuum of a the vector dot product. Orthogonalization of the monomial basis with the above scalar product leads to the definition of another family of polynomials, known as the Legendre polynomials
The Legendre polynomials are usually given with a different scaling such that , rather than the unit norm condition . The above results can be recovered by sampling of the interval at points , , , by approximation of the integral by a Riemann sum
|
||
The approach to compressing data suggested by calculus concepts is to form the sum of squared differences between and , for example for when carrying out linear regression,
and seek that minimize . The function can be thought of as the height of a surface above the plane, and the gradient is defined as a vector in the direction of steepest slope. When at some point on the surface if the gradient is different from the zero vector , travel in the direction of the gradient would increase the height, and travel in the opposite direction would decrease the height. The minimal value of would be attained when no local travel could decrease the function value, which is known as stationarity condition, stated as . Applying this to determining the coefficients of a linear regression leads to the equations
The above calculations can become tedious, and do not illuminate the geometrical essence of the calculation, which can be brought out by reformulation in terms of a matrix-vector product that highlights the particular linear combination that is sought in a liner regression. Form a vector of errors with components , which for linear regression is . Recognize that is a linear combination of and with coefficients , or in vector form
The norm of the error vector is smallest when is as close as possible to . Since is within the column space of , , the required condition is for to be orthogonal to the column space
The above is known as the normal system, with is the normal matrix. The system can be interpreted as seeking the coordinates in the basis of the vector . An example can be constructed by randomly perturbing a known function to simulate measurement noise and compare to the approximate obtained by solving the normal system.
Generate some data on a line and perturb it by some random quantities
∴ |
m=100; x=LinRange(0,1,m); a=[2; 3]; |
∴ |
a0=a[1]; a1=a[2]; yex=a0 .+ a1*x; y=(yex+rand(m,1) .- 0.5); |
∴ |
Form the matrices , , vector
∴ |
A=ones(m,2); A[:,2]=x; N=A'*A; b=A'*y; |
∴ |
Solve the system , and form the linear combination closest to
∴ |
atilde=N\b; [a atilde] |
(6)
∴ |
The normal matrix basis can however be an ill-advised choice. Consider given by
where the first column vector is taken from the identity matrix , and second is the one obtained by rotating it with angle . If , the normal matrix is orthogonal, , but for small , and are approximated as
When is small are almost colinear, and even more so. This can lead to amplification of small errors, but can be avoided by recognizing that the best approximation in the 2-norm is identical to the Euclidean concept of orthogonal projection. The orthogonal projector onto is readily found by -factorization, and the steps to solve least squares become
Compute
The projection of onto the column space of is , and has coordinates in the orthogonal basis .
The same can also obtained by linear combination of the columns of , , and replacing with its -factorization gives , that leads to the system , solved by back-substitution.
∴ |
Q,R=mgs(A); c=Q'*y; |
∴ |
aQR=R\c; [a atilde aQR] |
(7)
∴ |
The above procedure carried over to approximation by higher degree polynomials.
∴ |
m=100; n=6; x=LinRange(0,1,m); a=rand(-10:10,n,1); A=ones(m,1); |
∴ |
for j=1:n-1 global A A = [A x.^j]; end |
∴ |
yex=A*a; y=yex .+ 0.001*(rand(m,1) .- 0.5); N=A'*A; |
∴ |
b=A'*y; |
∴ |
atilde=N\b; Q,R=mgs(A); c=Q'*y; |
∴ |
aQR=R\c; [a atilde aQR] |
(8)
∴ |